반응형

INDEX
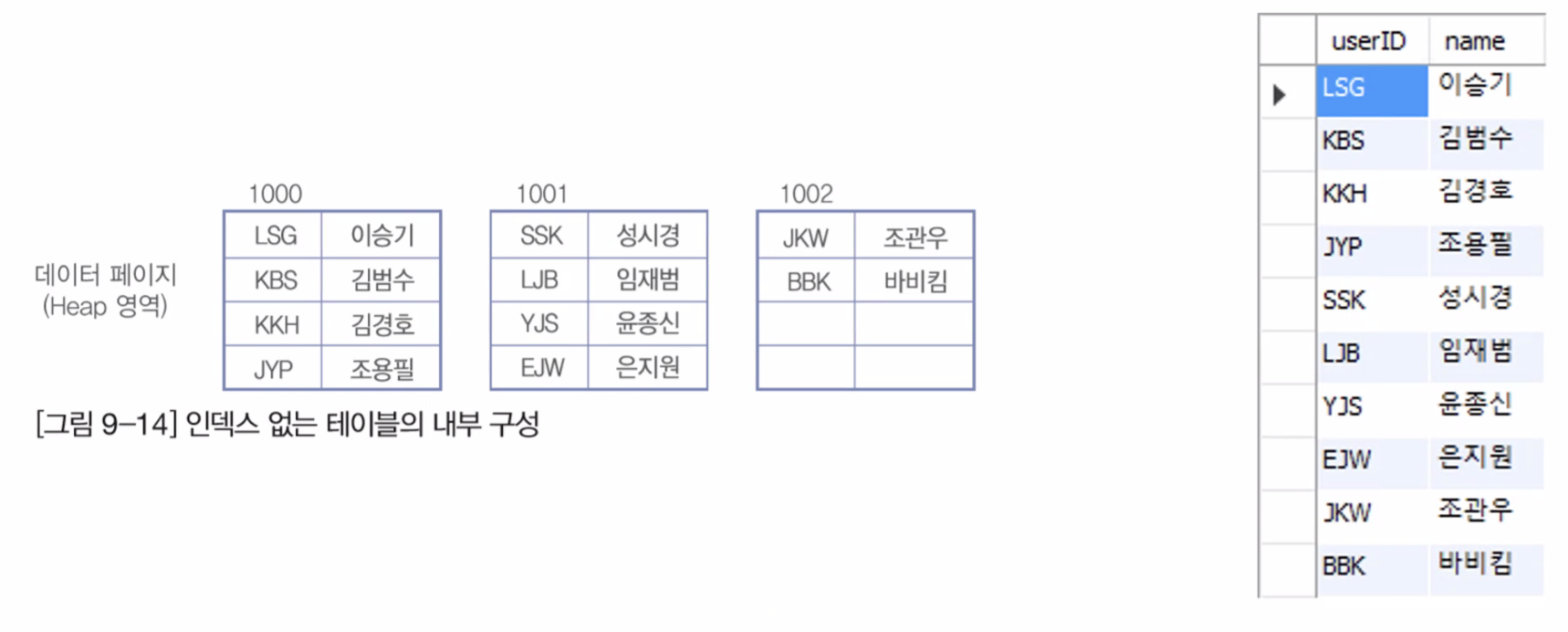
지정한 컬럼들을 기준으로 메모리 영역에 일종의 목차를 생성하는것.
INSERT, UPDATE, DELTE(Command)의 성능이 향상 될 수 있다.
▶ 장점
- 검색 속도가 빨라질 수 있다.
- 쿼리의 부하가 줄어들어 시스템 전체의 성능이 향상된다.
▶ 단점
- 인덱스가 DB 공간을 차지해 추가적인 공간이 필요해진다. 대략 DB크기의 10%정도 추가 공간이 필요하다.
- 처음 인덱스를 생성하는데 시간이 소요된다.
- 데이터의 변경 작업(Insert, Update, Delete)이 자주 일어나느 경우 성능이 저하될 수 있다.
인덱스의 종류
▶ Clustered Index
- '영어 사전' 같은 책과 비슷한 개념
- 테이블 당 한개만 지정 가능하다.
- 로우 데이터를 인덱스로 지정한 컬럼에 맞춰 자동 정렬한다.
▶ Secondary Index
- 책 뒤쪽에 찾아보기와 비슷한 개념
- 테이블당 여러개가 생성 가능하다.


인덱스의 속성

- Non_unique
- 0 = UNIQUE
- 1 = NonUNIQUE
- Key_name
- 인덱스 이름의 의미.
- PRIMARY = Clustered Index
- 컬럼의 이름 or 키의 이름 = Secondary Index
- Seq_in_index
- 해당 열에 여러개의 인덱스가 설정되었을 때의 순서. 대부분 1
- Null
- Null 값의 허용 여부.
- 비어있으면 NOT NULL
- Cardiality
- 중복되지 않은 데이터개수
- 데이터를 입력하면 analize table문을 수행해야 변경된다.
- Index_type
- 어떤 형태로 인덱스가 구성되었는지 보여준다.
- MySQL은 기본적으로 B-Tree 구조.
인덱스의 특징
▶ 클러스터 인덱스 생성
- PRIMARY KEY로 지정한 컬럼
- UNIQUE NOT NULL로 지정한 컬럼
▶ 세컨더리 인덱스 생성
- UNIQUE로 지정한 컬럼
- UNIQUE NULL로 지정한 컬럼
▶ PRIMARY KEY와 UNIQUE NOT NULL 이 존재
- PRIMARY KEY에 지정한 컬럼에 우선 클러스터 인덱스 생성
- PRIMARY KEY로 지정한 컬럼이 오름차순 정렬.
Clustered Index의 필요성
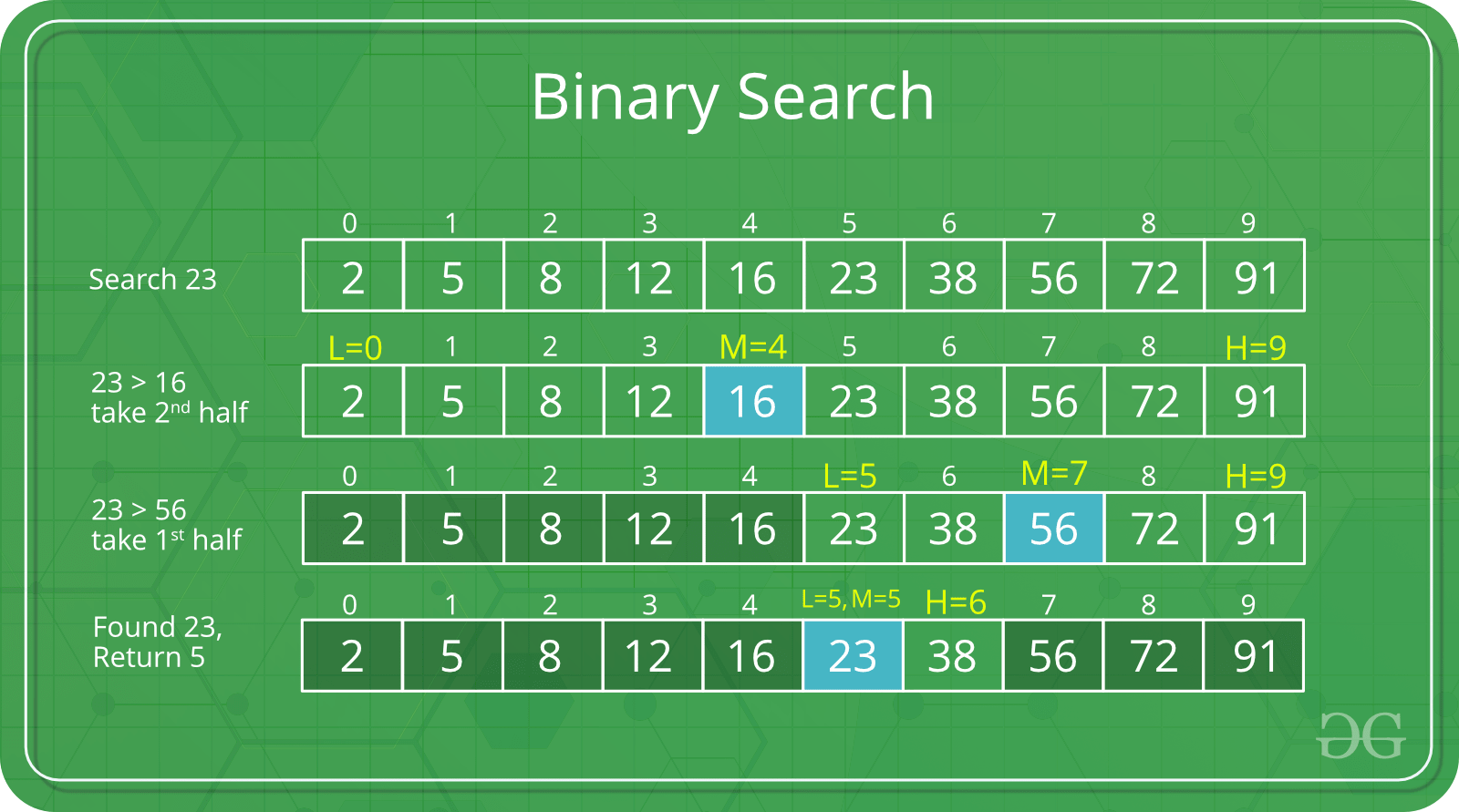
검색 방법에는 Full table scan, Binary search가 있다. Index는 사전에 미리 정렬이 되어있는 구조인 Binary search를 실행합니다.
B-Tree
자료 구조에 낭는 범용적으로 사용되는 데이터 구조
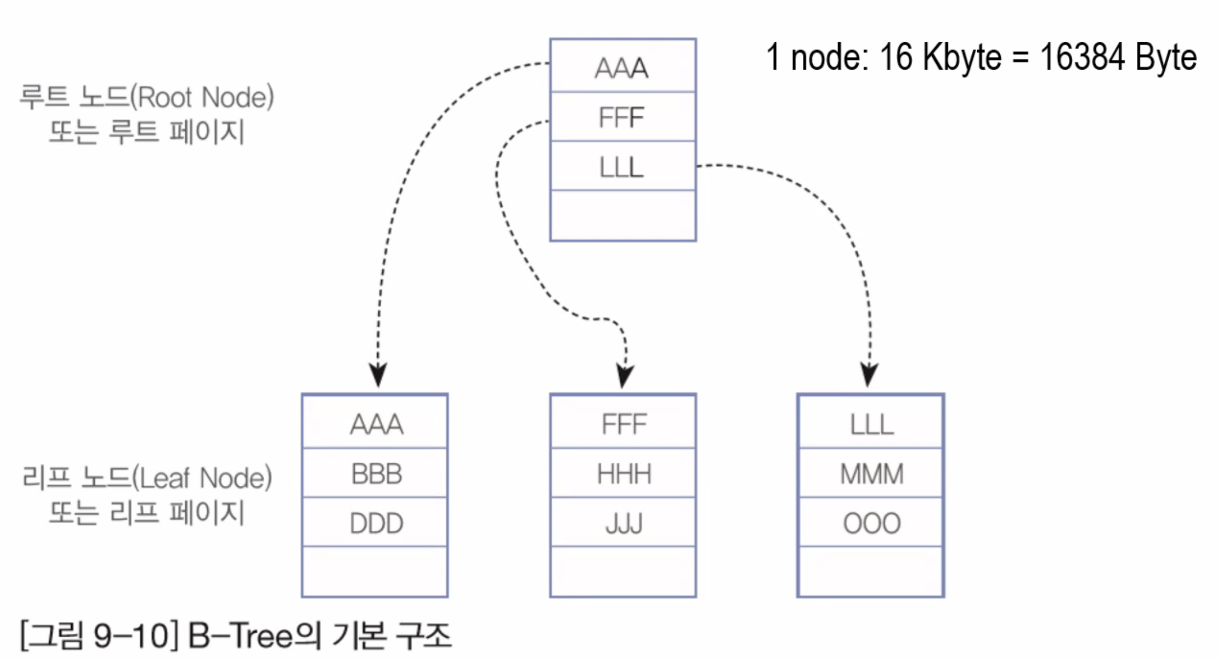
* 루트 노드 : 노드의 시작점
* 리프 노드 : 연결된 노드
▶ B-Tree Index 구조
- Root → Branch → Leaf → 디스크 저장소 순으로 저장됩니다.
- 인덱스의 두번째 컬럼은 첫 번째 컬럼에 의존한 상태로 정렬되어 있습니다.
- 두번째 컬럼의 정렬은 첫번째 컬럼이 같은 컬럼에서만 의미가 있습니다.
- 3번째, 4번째 컬럼이 있다면 3번째는 2번째에, 4번째는 3번째에 의존하는 관계입니다.
- 디스크에서 읽는 것은 메모리에서 읽는것보다 성능이 훨신 떨어집니다.
- 인덱스의 성능을 향상 시키는것은 디스크 저장소에 얼마나 덜 접근하게 하는것과 Root에서 Leaf까지 오고가는 횟수를 얼마나 줄이느냐에 달려있습니다.
- 인덱스의 갯수는 3~4개 정도가 적당합니다.
- 인덱스는 새로운 로우를 등록할때 마다 인덱스를 추가해야하며, 수정/삭제시 인덱스의 수정이 필요하여 성능상 이슈가 발생합니다.
- 인덱스는 공간을 차지하며, 많은 인덱스는 많은 공간을 차지하게됩니다.
- 옵티마이저가 잘못된 인덱스를 선택할 확률이 높습니다.

Index의 내부 작동
- 인덱스 구성 시 SELECT 문의 효율성이 향상 될 수 있습니다.
- 인덱스 구성 시 INSERT 문의 속도 저하가 발생합니다.
- 주어진 공간 이상으로 데이터가 입력되면 페이지의 분할이 일어나게됩니다.
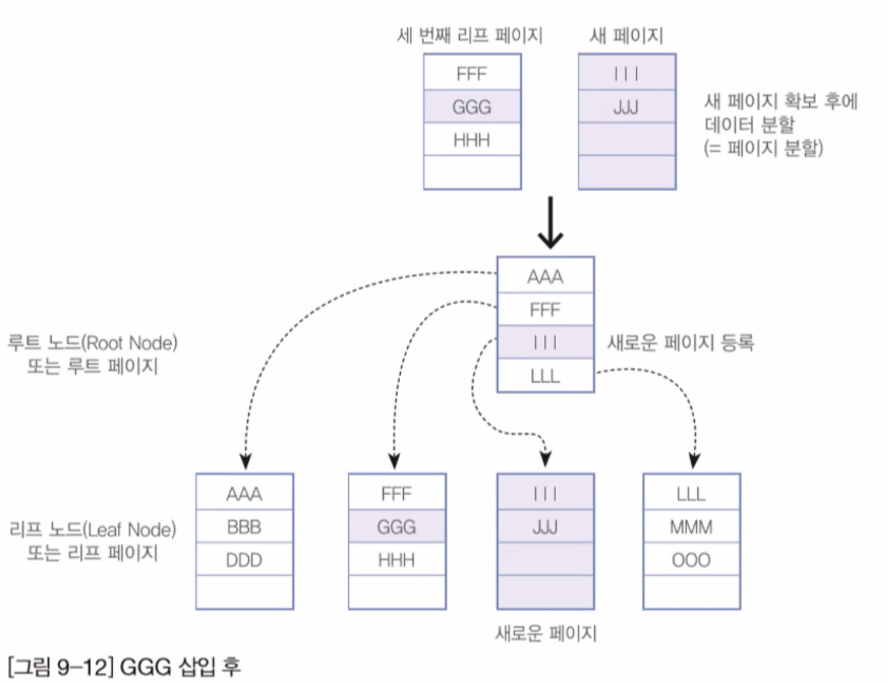
Index 구성 전/후
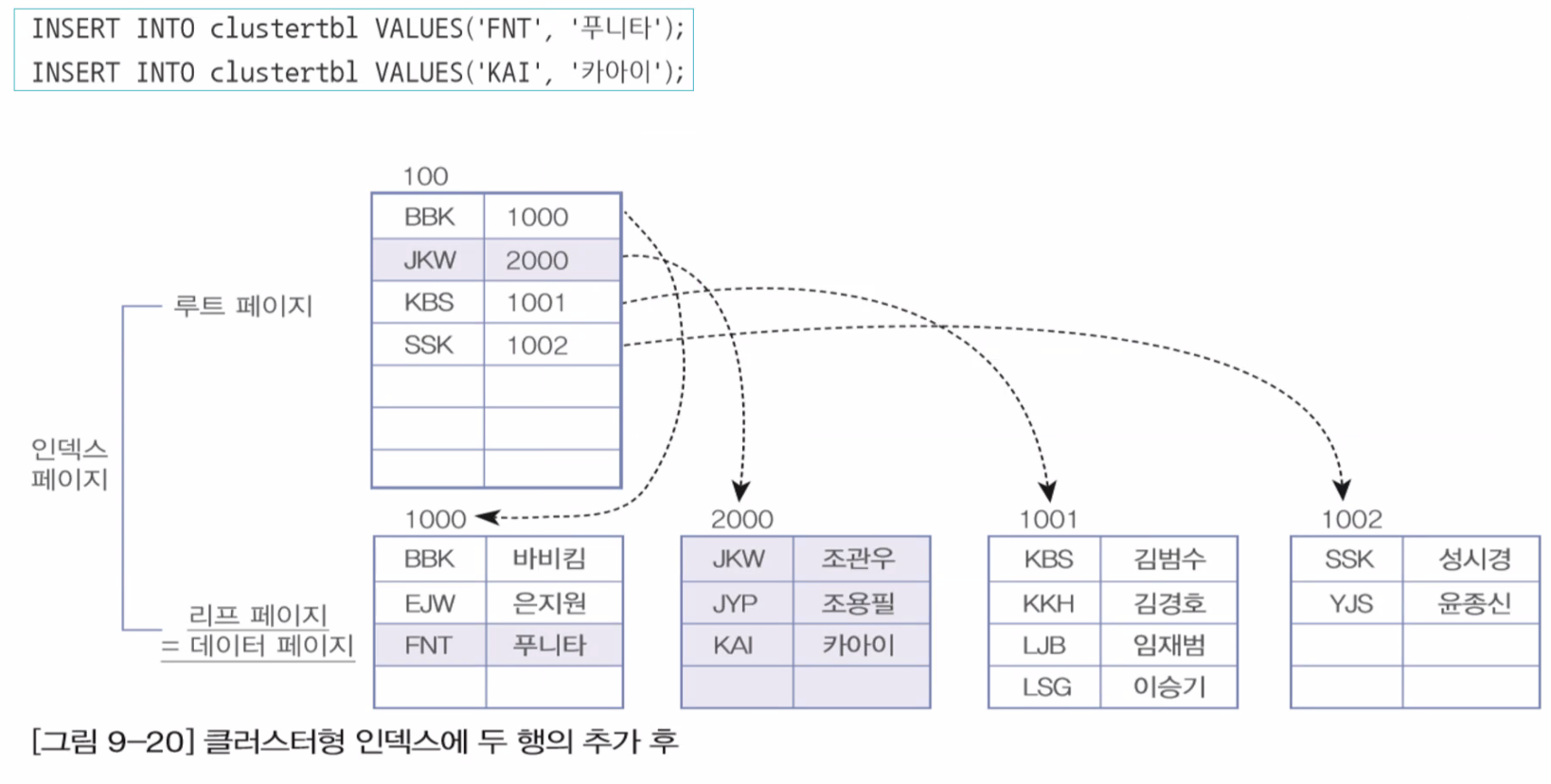
▶ 클러스터 인덱스 구성
- 데이터페이지가 재 정렬 됩니다.
- 대용량의 데이터가 입력된 상태에서 업무시간에 클러스터 인덱스를 생성하게 되면 심각한 시스템의 부하가 발생합니다.
- 세컨더리 인덱스보다 검색 속도가 더 빠르고 데이터의 입력, 수정, 삭제는 더 느립니다.
- 설정한 컬럼에 따라 시스템의 성능이 달라집니다.
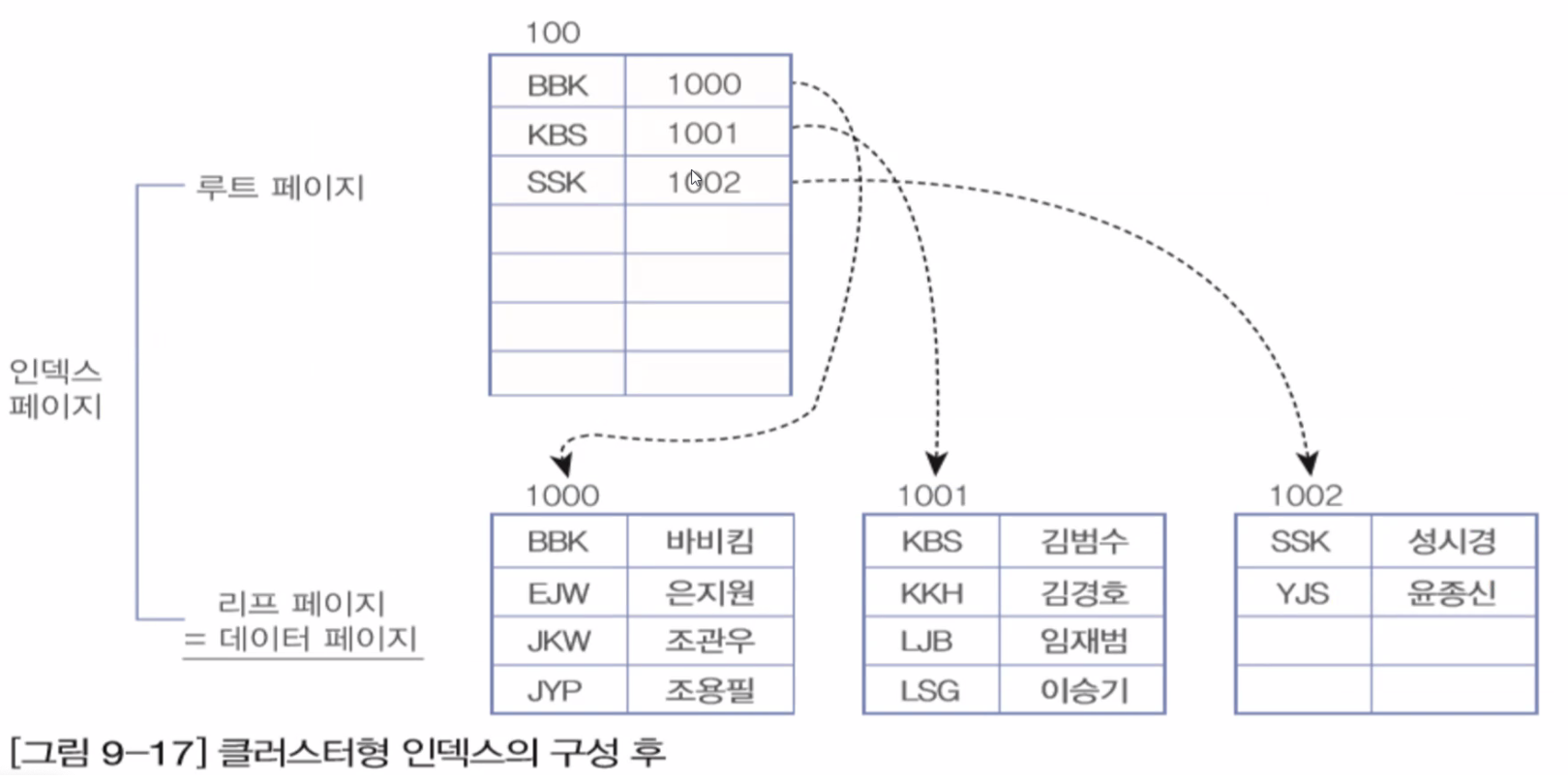
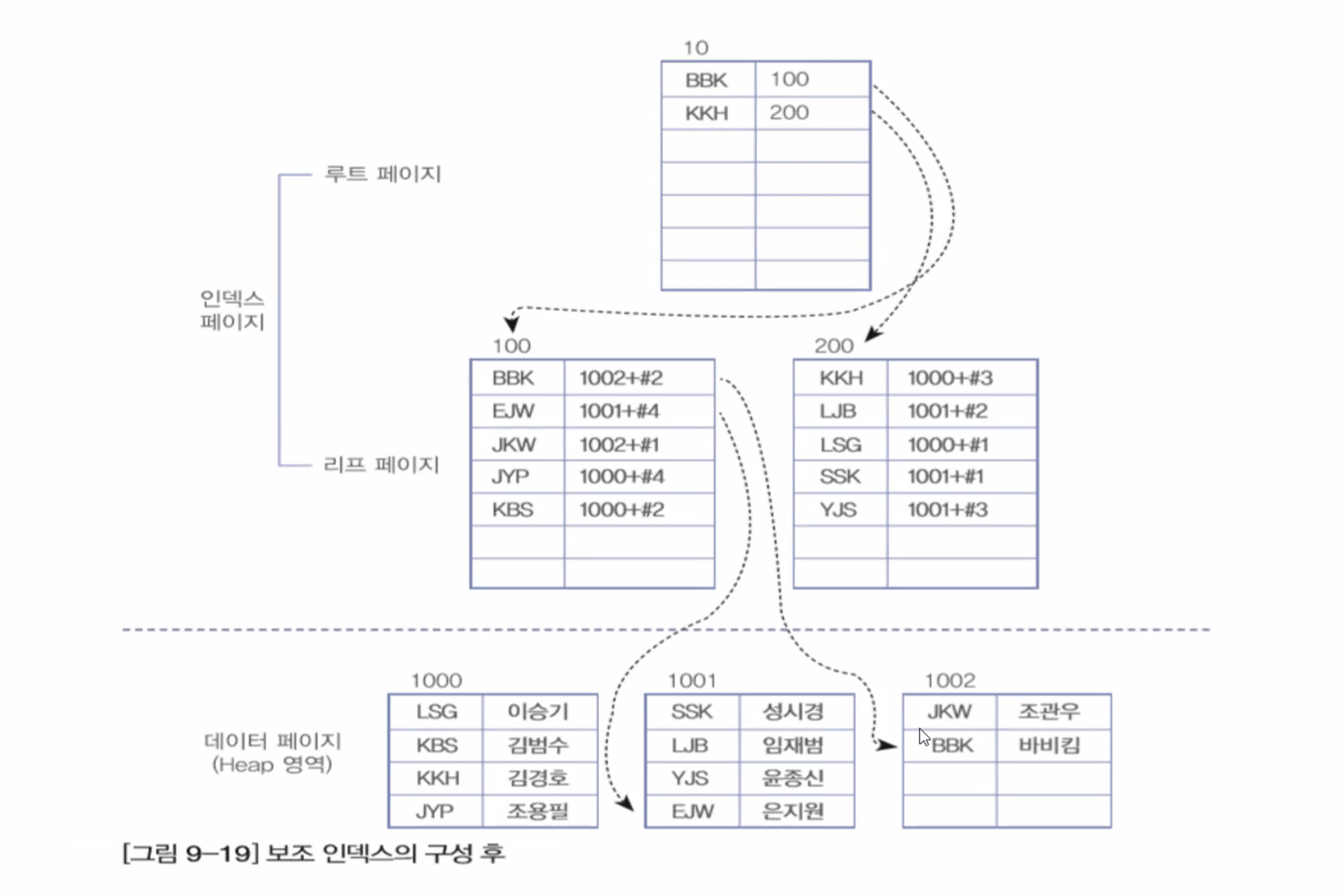
▶ 세컨더리 인덱스 구성
- 세컨더리 인덱스 생성시 별도의 페이지에 인덱스를 구성합니다.
- 세컨더리 인덱스는 구성후에도 데이터 페이지에서 보여지는 순서가 바뀌지 않습니다.
- 인덱스 페이지 내에서 정렬됩니다.
- 리프 페이지는는 데이터가 아닌 데이터의 주소 값(RID)를 가집니다.
- 클러스터 인덱스보다 검색 속도가 느리고 데이터의 입력, 수정, 삭제는 덜 느립니다.
- OLTP (On-Line Transaction Processing) I/U/D 자주 발생합니다.
- OLAP (On-Line Analytical Processing) I/U/D 자주 발생하지 않습니다.
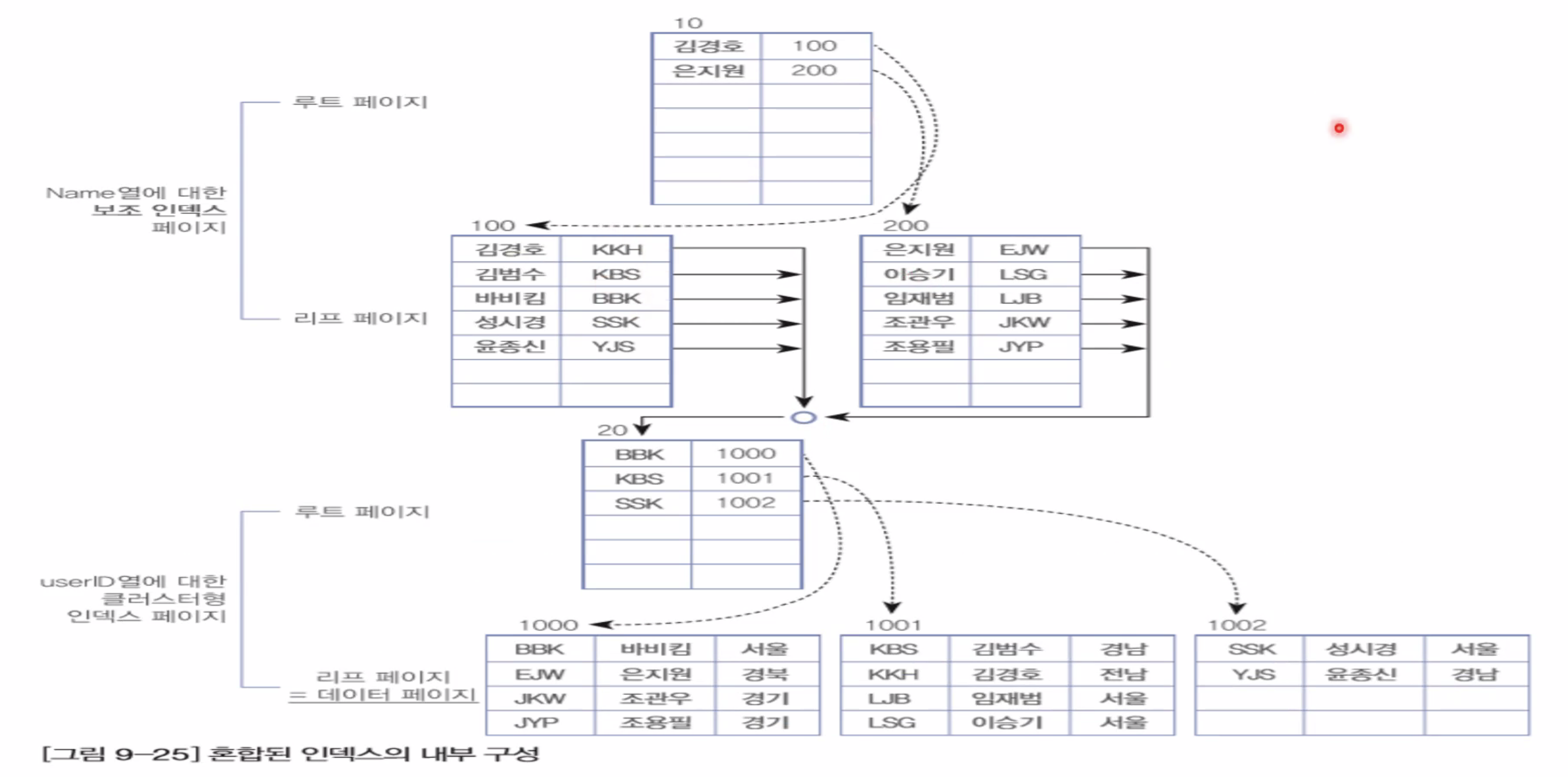
▶ 클러스터 인덱스 & 세컨더리 인덱스 혼합 구성
- 세컨더리 인덱스를 검색한 후 다시 클러스터 인덱스를 검색해야 하므로 약간의 손해를 볼 수 도 있겠지만, 데이터의 삽입 때문에 보조 인덱스를 대폭 재구성하게 되는 큰 부하는 걸리지 않습니다.
- 혼합되어 사용할 경우 클러스터 인덱스로 설정할 컬럼은 적은 자릿수의 컬럼을 선택하는것이 바랍직합니다.
- 인덱스를 검색하기 위한 1차 조건
- WHERE 절에 해당 인덱스를 생성한 컬럼의 이름이 나와야 합니다.
- WHERe 절에 해당 인덱스를 생성한 컬럼 일므이 나와도 인덱스를 사용하지 않는 경우도 많습니다.
인덱스 생성 형식
CREATE [UNIQUE | FULLTEXT | SPATIAL] INDEX index_name
[index_type]
ON tbl_name (key_part, ...)
[index_option]
[algorithm_option | lock_option] ...
key_part :
{col_name [(length) | (expr)] [ASC | DESC]
index_option :
KEY_BLOCK_SIZE [=] value
| index_type
| WITH PARSER parser_name
| COMMENT 'string'
| {VISIBLE | INVISIBLE}
index_type :
USING {BTREE | HASH}
algorithm_option :
ALGORITHM [=] {DEFAULT | INPLACE | COPY}
lock_option :
LOCK [=] {DEFAULT | NONE | SHARED | EXCLUSIVE}
▶ 보조 인덱스 생성 구문
ALTER TABLE 테이름 이름 ADD INDEX 제약명 (컬럼이름);

인덱스 삭제 형식
DROP INDEX index_name ON tbl_name
[algorithm_option | lock_option] ...
algorithm_option :
ALGORITHM [=] {DEFAULT | INPLACE | COPY}
lock_option :
LOCK [=] {DEFAULT | NONE | SHARED | EXCLUSIVE}
▶ 삭제문
DROP INDEX 인덱스 이름 ON 테이블 이름;
인덱스의 성능 비교
- 데이터의 중복도가 높은 경우 인덱스를 사용하는것이 효율적입니다.
- 인덱스의 관리 비용과 INSERT 등의 구문에서는 오히려 성능이 저하 될 수 있다는 점을 고려하면 인덱스가 반드시 바람직 하다고 보기는 어렵습니다.
상황에 따른 인덱스 생성 여부
- 인덱스는 컬럼 단위에 생성됩니다
- 두 개 이상의 열을 조합해서 인덱스 생성이 가능합니다.
- WHERE절에서 사용되는 열에 인덱스를 만들어야 합니다.
- 테이블 조회시 WHERE절의 조건에 해당 열이 나오는 경우에만 인덱스 주로 사용합니다.
- WHERE절에 사용되더라도 자주 사용해야 가치가 있습니다.
- SELECT문이 자주 사용되어야 효과적입니다.
- INSERT문이 자주 사용되고 생성된 인덱스가 클러스터라면 효율이 감소합니다.
- 데이터의 중복도가 높은 컬럼은 인덱스를 만들어도 효과가 없습니다.
- 인덱스의 관리 비용 때문에 인덱스가 없는 편이 나은 경우도 있습니다.
- 외래 키 지정한 열에는 자동으로 외래키 인덱스가 생성됩니다.
인덱스를 생성해야 하는 경우와 그렇지 않은 경우
- JOIN에 자주 사용되는 열에는 인덱스를 생성해 주는 것이 좋습니다.
- INSERT / UPDATE / DELETE가 얼마나 자주 일어나는지 고려해야 합니다.
- 인덱스는 단지 읽기에서만 성능이 향상됩니다.
- 데이터의 변경에서는 오히려 비효율적일 수 있습니다.
- 클러스터 인덱스가 테이블에 존재하지 않는 것이 좋은 경우도 있습니다.
- 사용하지 않는 인덱스는 제거 합니다.
- 공간 확보 및 데이터의 입력시 발생되는 부하를 줄입니다.
반응형
'SQL' 카테고리의 다른 글
| [MySQL] Table Space (1) | 2022.09.20 |
|---|---|
| [MySQL] VIEW (0) | 2022.09.20 |
| [MySQL] GROUP BY (0) | 2022.09.17 |
| [MySQL] 데이터베이스 객체, 스키마 (0) | 2022.09.17 |
| [MySQL] SubQuery (0) | 2022.09.17 |