정규화는 쉽다.
하지만 왜 정규화를 쓰는지 모르기 때문에 정규화가 어려운 것이다.

Entity 조직
- 속성과 Entity를 grouping 한다.
- 조직 단계에서 Entity가 명확해진다
- 조직 단계에서 추가적인 Entity가 도출될 수 있다.

관계 도출
- 관계는 PK, FK 등으로 구현한다.
- Entity와 Entity 간의 관계는 동사로 표현한다.

개념적 모델링(ERD) 시나리오
1. ERD(개념적 모델링)를 엑셀을 이용하여 테이블을 작성한다.

→ 문제점
- 작성자, 댓글아이디의 data가 중복하여 where문을 적용 할 수 없다. = Non Atomic Colums
2. 중복성을 해결한다.

→ 문제점
- 데이터의 중복이 발생한다. (제목, 본문, 작성일)
- DB 이상현상(DB Anomaly)이 발생한다.
→ 해법 : 정규화.
* DB Anomaly (DB 이상현상)
▶ 정의
- 데이터의 중복으로 인하여 데이터의 삽입, 삭제, 갱신을 할 경우 발생되는 부작용.
▶ 종류
삽입 이상
- 데이터 삽입시 원치 않은 데이터를 같이 넣어야 하는 이상현상.
- 일반적으로 관계를 잘못 맺을 때 발생한다.
삭제 이상
- 데이터 삭제 시 다른 데이터까지 같이 삭제되는 이상현상.
갱신 이상
- 데이터 수정 시 중복으로 인해 데이터의 불일치가 발생하는 이상현상.
방법론 - RDB에 중복이 발생하지 않도록 Data를 입력하는 일반적인 방법론
그것이 정규화다.
내 테이블의 문제점이 무엇인지 파악하는 것이 정규화를 아는 것보다 중요하다.
정규화 (Normalization)
- RDB 설계 시 중복의 최소화, 이상현상 방지, 성능개선을 위한 설계 프로세스다.
- 정규화는 일반적인 표를 RDB에 맞는 표로 개선한다.

제1 정규화
제1 정규화의 정의
- 반복되는 속성을 제거하여 모든 속성의 원자 도메인(원자성, Atomic cloumns)을 가질 수 있도록 하는 정규화.
- Atomic Columns : Column이 하나의 값/하나의 의미를 가져야 한다.
제1 정규화의 특징
- m:n 관계를 1:n관계로 변경한다.
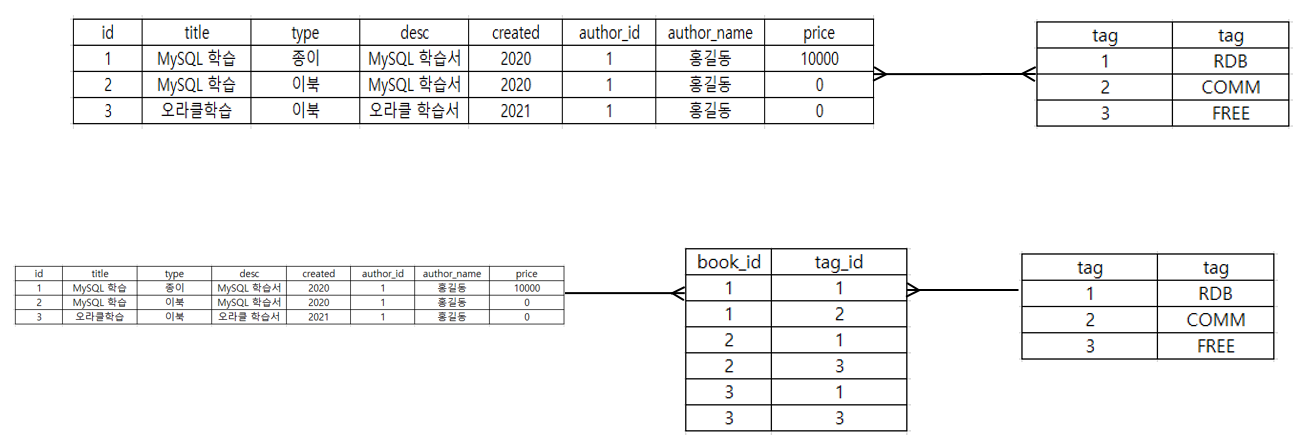
☞ 제1 정규화 적용 예제

→ 문제점
- tag가 중복된다.
- Where 조건이 적용되지 않는다.
- Join을 할 수 없다.
- Row를 도출하기가 까다로워진다.
- 해법 1.
- tag의 종류의 수만큼 tag Column을 추가한다.

→ 문제점
- 태그의 수가 많아질 수 록 복잡성이 증가한다.
- 규칙성이 없기 때문에 DBMS의 입장에서 성능이 떨어질 수 있다.
- 확장성, 유연성이 대폭 사라진다.
+ 해법 2.
태그를 분리한다.

Mapping Table을 작성한다.
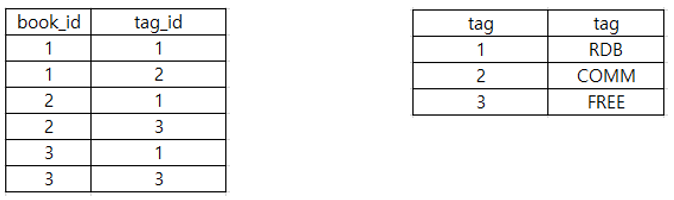
JOIN이 증가할 수 록 쿼리가 늘어나 시스템의 성능이 하락하여 반 정규화를 실행한다.
1NF(제1 정규화) 적용 시나리오
main table이 있다.
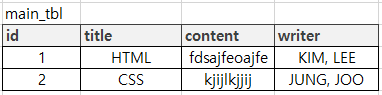
1. 위 테이블의 문제점
- writer가 중복되어 WHERE 조건을 실행 할 수 없다.
- row를 도출하기 어렵기 때문에 JOIN을 형성하기 어렵다.
2. 해결 방안
해결방안 1
- writer의 종류 수 만큼 Column을 제작한다.
장점 : writer의 종류가 적을 시 가장 간단하고 빠른 해결 방법일 수 있다.
단점 : writer의 종류가 많아 질 수 록 제작에 소모되는 시간이 많아지며 복잡성이 증가하고 데이터의 량이 불필요하게 많아져 공간 활용성이 저하된다.
해결방안 2
- writer를 분리하여 1차 정규화를 수행한다.
장점 : 중복성이 해결되며 유연성과 확장성 향상되어 더 많은 종류가 입력되어도 복잡성 없이 해결 가능하고 규칙성이 향상되어 DBMS의 성능이 향상된다.
단점 : 종류의 수가 적을 시 방법 1 보다 제작에 소모되는 시간이 더 많아질 수 있다.

1NF (제1 정규화)가 좋은 해결방안인 이유
- 중복성을 최소화 함으로서 데이터의 공간 활용성 측면에서 긍정적이며 데이터 입력 시 중노동으로 이어지지 않는다.
- 유연성과 확장성이 향상되어 추가적인 데이터가 발생하여도 순조롭게 입력이 가능하다.
- 규칙이 생김으로서 DBMS의 성능이 향상된다.
제2 정규화 (2NF)
정의
- 제 1정규형을 만족하는 테이블에서 부분 종속성을 제거하여 완전 함수 종속성을 만족하는 정규형
- 복합키(Composite Key)를 사용하지 않는다면 제2 정규화를 진행할 수 없다.
※ 완전 함수적 종속 : X → Y (X값에 의해 Y값이 하나가 나온다.)
- X : 독립변수 (원인)
- Y : 종속변수 (결과)
- 모든 Y는 X에 종속된다.
- 즉 모든 데이터는 키에 종속된다.
- Y 절편 - 원인(X)이 0일 때
- X 절편 - 결과(Y)가 0일 때
제 2 정규화 처리
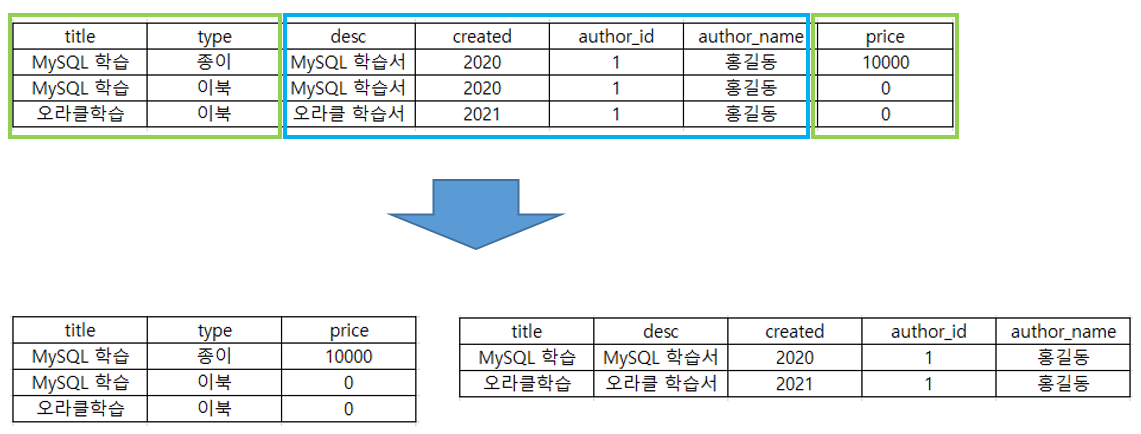
- key가 title + type 일 때 price는 key에 종속되나 desc는 title에만 종속한다.
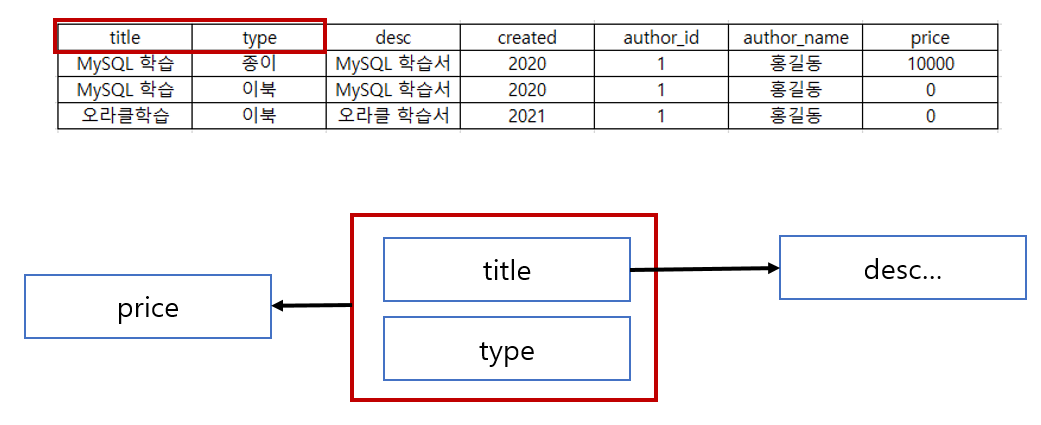
→ 문제점
- 부분 함수 종속은 테이블의 중복을 일으킨다.
→ 해법
- 중복되는 부분 종속성을 분리한다.
- 완전 함수 종속성을 만족하는 Column을 남긴다.
* key가 복합키로 이루어져야 완전 함수 종속성이 성립될 수 있다.
제3 정규화의 정의
- 이행함수 종속성을 제거(No transtive depentencies)하는 정규화.
이행 함수 종속성
- X가 Y에 종속된다. X → Y
- Y가 Z에 종속된다. Y → Z
- X가 Y에 종속되고 Z에 종속된다. X → Y → Z
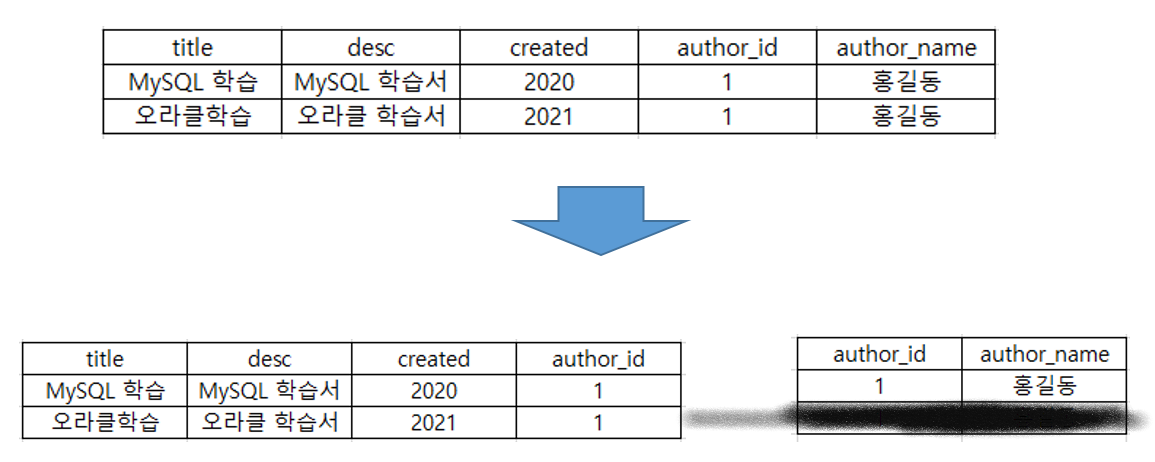
제3 정규화의 처리
- desc, created, author_id는 title에 종속적이다.
- author_name은 author_id에 종속적이다.

author_name을 분리한다.
☞ 정규화 예제
아래 테이블을 정규화하시오
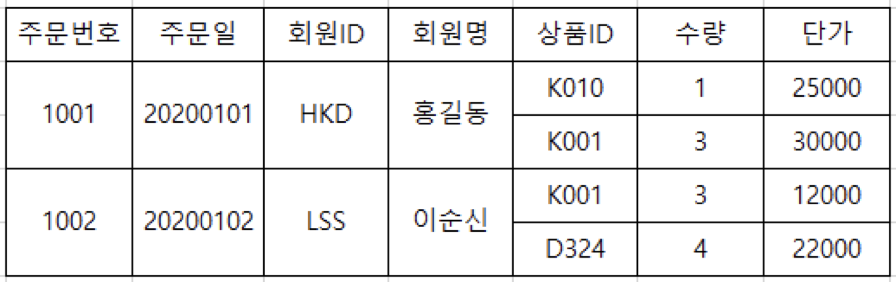
1.main table의 Atomic Colums을 찾고 아닌 Columns을 분리한다.
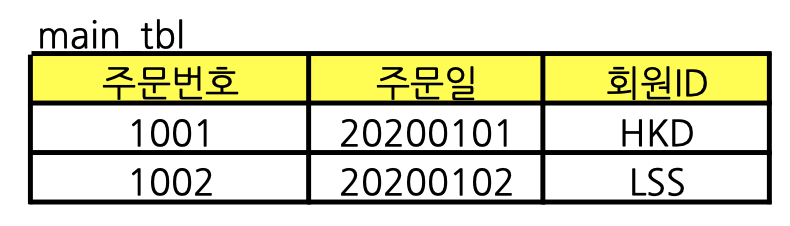
2. member table을 분리한다.
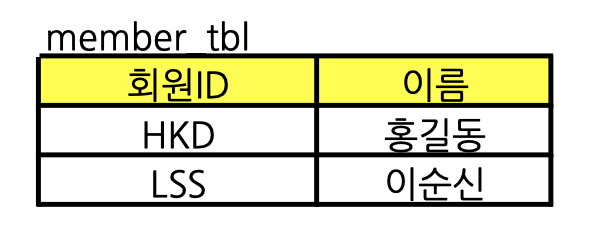
3. goods table을 분리한다
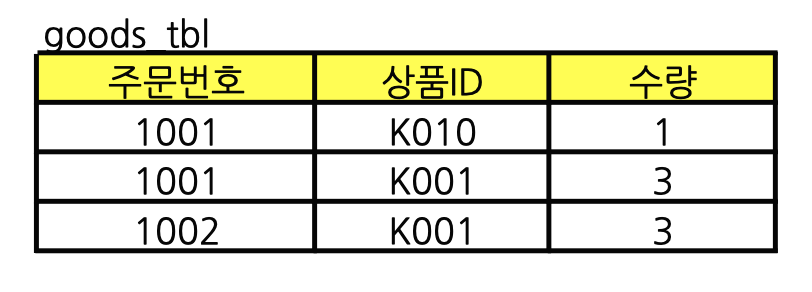
4. price table을 분리한다.
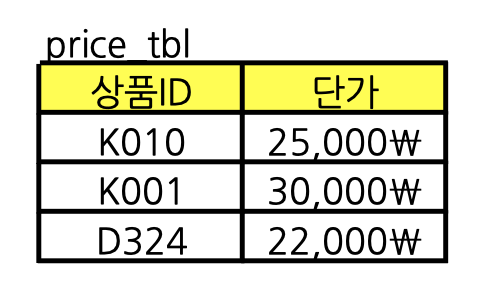
중복되는 Column을 Unique 하게 만들어 Mapping을 하는 것이 정규화다.
정규화를 통해 속도가 낮아지면 정규화에 목적을 상실한 것이다.
'DataBase' 카테고리의 다른 글
| [DataBase] ORM (0) | 2023.02.01 |
|---|---|
| [Data Modeling (데이터 모델링)] (0) | 2022.04.02 |
| Database (0) | 2022.03.25 |
| DBMS (0) | 2022.03.25 |