
그룹연산
- 특정 기준을 적용하여 몇 개의 그룹으로 분할하여 처리하는 것.
- 복잡한 데이터를 어떤 기준에 따라 여러 그룹으로 나눠서 관찰하기에 좋습니다.
- 데이터를 집계, 변환, 필터링하는데 효율적입니다.
▷ 그룹연산의 단계
- split(분할) : 데이터를 특정 조건에 의해 분할.
- apply(적용) : 데이터를 집계, 변환, 필터링하는데 필요한 메서드를 적용합니다.
- combine(결합) : 2단계의 처리 결과를 하나로 결합합니다.

▶ groupby()
- 데이터프레임의 특정 컬럼을 기준으로 데이터프레임을 분할하여 그룹 객체를 반환합니다.
- 기준이 되는 컬럼은 1개도 가능하며 여러 컬럼을 리스트로 입력도 가능합니다.
DataFrame.groupby()
분할 단계
▷ 데이터를 가져옵니다.
df_t1 = sns.load_dataset('titanic').loc[:, ['age', 'sex', 'class', 'fare', 'survived']]
▷ class 컬럼의 유니크 값을 확인합니다.
df_t1['class'].unique()
# ['Third', 'First', 'Second']
▷ groupby()로 class컬럼을 기준으로 분할하여 저장합니다.
g1 = df_t1.groupby(['class'])
# len(g1)
# 3
▷ 그룹 각각의 컬럼의 평균을 구합니다.
g1.mean()
df_t1.groupby(['class']).mean()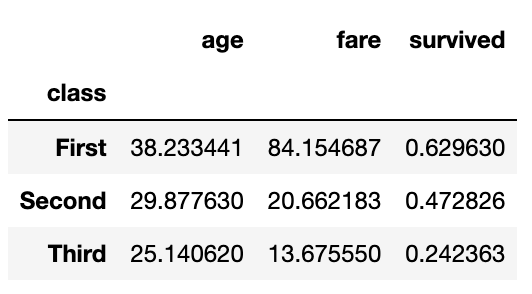
▷ 특정 그룹을 잡습니다.
group.get_group(컬럼명)df_t1.groupby(['class']).get_group('Third')
▷ class, sex 컬럼으로 그룹을 잡습니다.
g2 = df_t1.groupby(['class', 'sex'])
▷ g2 그룹의 평균을 구합니다.
g2.mean()
▷ 3등석의 여성 데이터를 출력합니다.
g2.get_group(('Third', 'female'))
적용-결합 단계
- 그룹 객체에 다양한 연산을 적용할 수 있습니다.
- mean, max, min, sum, count, size, var, std, describe, info, first, last 등 집계 기능
▷ g1의 표준편차를 구하여 데이터 프레임으로 반환합니다.
g1.std()
▷ g1의 fare 컬럼의 표준편차를 구합니다. 시리즈로 반환합니다.
g1.fare.std()
# class
# First 78.380373
# Second 13.417399
# Third 11.778142
# Name: fare, dtype: float64
▶ agg()
- 매핑함수
- 사용자 정의 함수를 그룹 객체에 적용합니다.
▷ 최대값 - 최소값을 구하는 함수를 생성하여 g2에 적용합니다.
def min_max(x) :
return x.max() - x.min()
g2.agg(min_max)
그룹 연산
- 여러 함수를 각 열에 동일하게 적용하여 집계합니다.
- 각 열마다 다른 함수를 적용합니다.
▷기본 구문
group.agg([함수1, 함수2, 함수3, ...])
group.agg({'컬럼1' : 함수1, ...})
▷ g1의 최소값과 최대값을 구합니다.
g1.agg(['min', "max"])
▷ g1의 fare컬럼에 최대값, 최소값, age 컬럼에는 평균을 구합니다.
g1.agg({'fare' : ['min', 'max'], 'age':'mean'})

▶ transform()
- agg()는 각 그룹별 데이터에 함수를 구분 적용하고 그룹별 결과를 집계하고 transform()은 그룹별 각 원소에 함수를 적용.
- 그룹별 집계 대신 각 원소의 본래 행 인덱스와 컬럼 이름을 기준으로 결과를 반환합니다.
▷ transform() 메서드를 이용하여 age컬럼의 데이터를 z-score로 변환 합니다.
# 표준점수를 구하는 함수
def z_score(x) :
return (x - x.mean()) / x.std()
g1.age.transform(z_score)
# 0 -0.251342
# 1 -0.015770
# 2 0.068776
# 3 -0.218434
# 4 0.789041
# ...
# 886 -0.205529
# 887 -1.299306
# 888 NaN
# 889 -0.826424
# 890 0.548953
# Name: age, Length: 891, dtype: float64
그룹객체 필터링
▶ filter()
▷ 데이터의 개수가 200개 이상인 그룹만 가져옵니다.
g1.filter(lambda x : len(x) > 200)
▷ age의 평균값이 30 미만은 그룹만 가져옵니다.
g1.filter(lambda x : x['age'].mean() < 30)

▶ apply()
- 개별 원소 특정 함수에 1:1로 매칭.
- 그룹 객체에도 적용 가능.
▷ g1의 class컬럼 각 그룹별 요약 통계 정보를 집계합니다.
g1.apply(lambda x: x.describe())
▷ z-score를 출력합니다.
g1.apply(z_score)
g1.age.apply(z_score)
▷ g1 그룹의 age컬럼의 데이터 평균이 30보다 작은 그룹만 필터링하여 출력합니다.
age_ft = g1.apply(lambda x : x.age.mean() < 30)
for i in age_ft.index :
if age_ft[i] == True :
print(g1.get_group(i))filter로 출력.
g1.filter(lambda x : x.age.mean() < 30)
멀티인덱스
▶ 데이터를 불러와 그룹화합니다.
df_t = sns.load_dataset("titanic").loc[:, ['survived', 'class', 'age', 'sex', 'fare']]
g3 = df_t.groupby(['class', 'sex'])
▶ 그룹 연산을 실행합니다.
gdf = g3.mean()
▶ loc로 시리즈 데이터를 확인합니다.
# 다중 인덱스
gdf.loc[('First', 'female'), :]
# survived 0.968085
# age 34.611765
# fare 106.125798
# Name: (First, female), dtype: float64
▶ xs() 로 안쪽의 데이터를 확인합니다.
# 멀티 인덱스시 안쪽의 인덱스를 잡는다.
gdf.xs("male", level='sex')
▶ 로우 선택
▷ 컬럼 인덱스가 First인 로우 선택
gdf.xs('First')
▷ 컬럼 인덱스가 ('Frist', 'female') 인 로우 선택
gdf.xs(('First', 'female'))
# survived 0.968085
# age 34.611765
# fare 106.125798
# Name: (First, female), dtype: float64
▷ 컬럼 인덱스의 sex레벨이 male인 로우 선택
gdf.xs('male', level='sex')
▶ 컬럼 선택
axis=1 로 설정합니다.
▷ 컬럼 인덱스가 survived 인 데이터를 선택.
gdf.xs('survived', axis=1)
# class sex
# First female 0.968085
# male 0.368852
# Second female 0.921053
# male 0.157407
# Third female 0.500000
# male 0.135447
# Name: survived, dtype: float64
▷ 컬럼 인덱스가 ('survived', 'age')인 데이터를 선택.
gdf.xs(['survived', 'fare'], axis=1)
※ pivot table을 생성합니다.
https://cruella-de-vil.tistory.com/227
[Python] Pivot Table
Pivot Table 엑셀에서 사용하는 피벗테이블과 비슷한 기능을 처리합니다. 4가지 필수 요소 컬럼 인덱스 로우 인덱스 데이터 값 (values) 데이터 집계 함수 (aggfunc) 피벗 테이블 변환 이후 xs()를 사용하
cruella-de-vil.tistory.com
gdf_2 = df_t.pivot_table(columns="survived",
index=("class", "sex"),
values=("age", "fare"),
aggfunc=('mean', 'sum'))

▷ survived 레벨이 1인 데이터를 선택합니다.
gdf_2.xs(1, level='survived', axis=1)
'Python' 카테고리의 다른 글
| [Python] Stack & Queue (0) | 2022.10.08 |
|---|---|
| [Python] Pivot Table (0) | 2022.10.06 |
| [Python] 데이터 프레임 연결 (0) | 2022.10.06 |
| [Python] Boolean Indexing (0) | 2022.10.06 |
| [Python] 컬럼 순서 변경 (0) | 2022.10.06 |