
빅데이터 분석 절차

데이터 수집 → EDA, 전처리 → Decision Tree 선정 → 학습 → 결과 확인
→ (정성적 분석) → (위험성 분석) → 시스템 적용 → 모델 활용 예측
3. 모델 선택
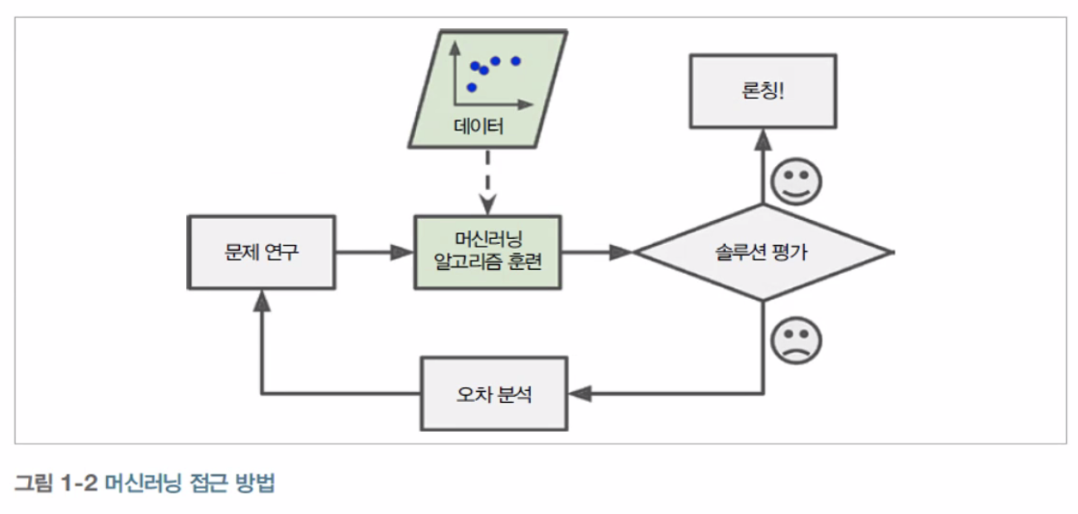
Maschine Learning.
컴퓨터 프로그램이 알고리즘을 사용하여 데이터에서 패턴을 찾는 인공 지능 애플리케이션.


▶ 머신러닝을 사용하는 이유
- 전통적 프로그래밍 기법은 규칙이 점점 길고 복잡해지므로 유지보수가 매우 힘듬.
- 머신러닝 기법에 기반을 둔 스팸 필터는 일반 메일에 비해 스팸에 자주 나타나는 패턴을 감지하여 어떤 단어와 구절이 스팸 메일을 판단하는데 좋은 기준인지 자동으로 학습함.
- 전통적인 방식으로는 너무 복잡하거나 알려진 알고리즘이 없는 분야 (예 : 음성인식)

▶ 머신러닝의 장점
- 기존 솔루션으로 많은 수동 조정과 규칙이 필요한 문제 :
- 하나의 머신러닝 모델이 코드를 간단하게 만들고 전통적인 방법보다 더 잘 수행되도록 할 수 있음.
- 전통적인 방식으로는 해결 방법이 없는 복잡한 문제 :
- 가장 뛰어난 머신러닝 기법으로 해결 방법을 찾을 수 있음.
- 유동적인 환경 :
- 머신러닝 시스템은 새로운 데이터에 적응 가능
- 복잡한 문제와 대량의 데이터에서 통찰을 얻음.
▶ 어플리케이션의 사례
- 이미지 분류 작업 : 생산 라인에서 제품 이미지를 분석해 자동으로 분류.
- 시맨틱 분할 작업 : 뇌를 스캔하여 종양 진단.
- 텍스트 분류(자연어 처리) : 자동으로 뉴스 기사 분류.
- 토론 포럼에서 부정적인 코멘트를 자동으로 구분.
- 텍스트 요약 : 긴 문서를 자동으로 요약.
- 자연어 이해 : Chatbot 또는 개인 비서 제작.
- 회귀 분석 : 회사의 내년도 수익 예측.
- 음성 인식 : 음성 명령에 반응하는 앱.
- 이상치 탐지 : 신용 카드 부정 거래 감지.
- 군집 작업 : 구매 이력을 기반으로 고객을 나누고 각 집합마다 다른 마케팅 전략을 계획.
- 데이터 시각화 : 고차원의 복잡한 데이터셋을 명확하고 의미 있는 그래프로 표현.
- 추천 시스템 : 과거 구매 이력을 기반으로 고객이 관심을 가질 수 있는 상품 추천.
- 강화 학습 : 지능형 게임 bot 제작.
▶ 머신러닝의 주요 도전 과제
머신러닝의 주요 작업은 학습 알고리즘을 선택해서 어떤 데이터에 훈련시키는 것.
▷ 나쁜 데이터
- 충분하지 않은 양의 훈련 데이터
- 대표성 없는 훈련 데이터
- 낮은 품질의 데이터
- 관련 없는 특성
▷ 나쁜 알고리즘
- 훈련 데이터 과대적합
- 훈련 데이터 과소적합

▶ 데이터 vs 머신러닝
양질의 데이터가 있다는 가정하에 성능이 좋지 않은 머신러닝을 사용했을 때 좋은 결과를 얻을 수 있다.
▶ PYTHON VS R


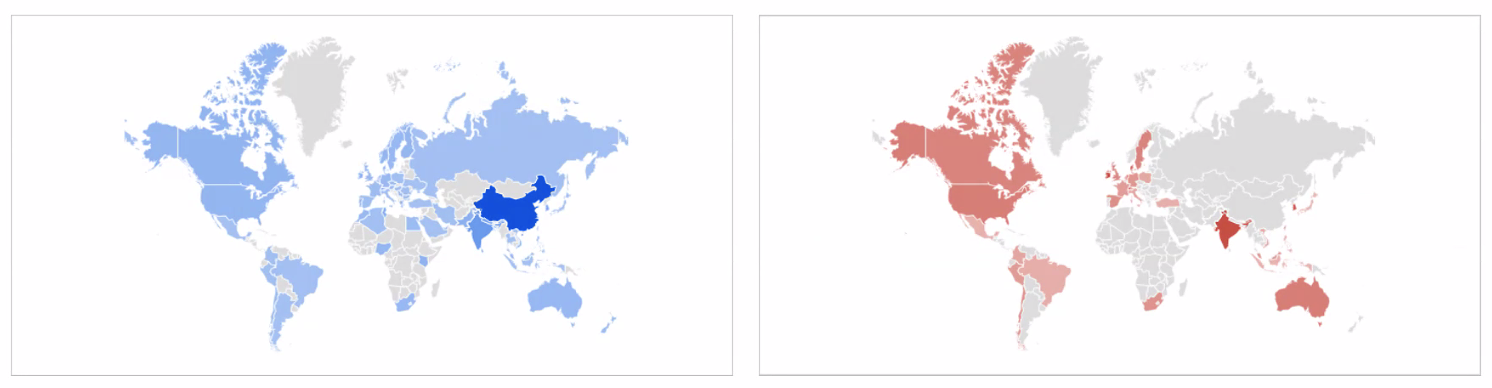
▶ 딥러닝 프레임워크 파이썬 우선 정책

▶ Python Machine Learning
- Supervised Learning(지도 학습)
- 각각의 데이터를 지명한다.
- Unsupervised Learning(비지도 학습)
- 비슷한 항목들끼리 묶는다.
- 90% 사용.

▶ Supervised Learning
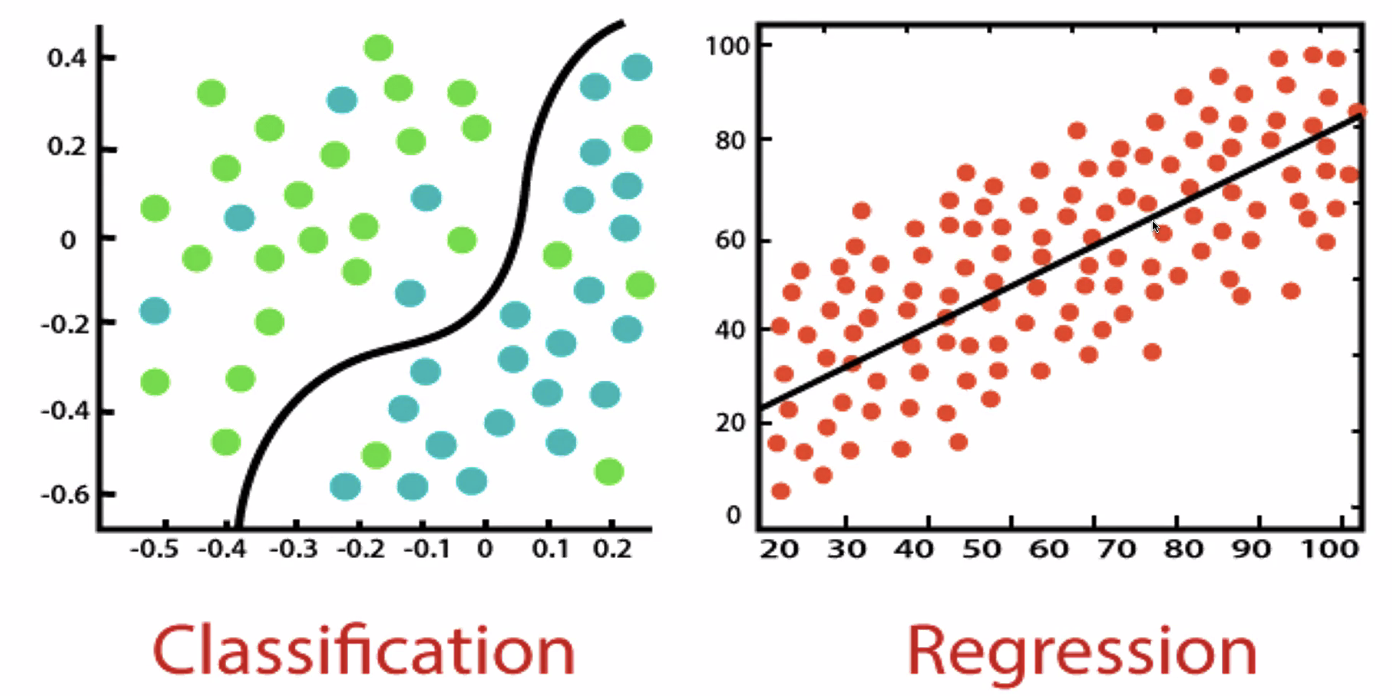
- Naive Bayes, Bayes : 통계와 생성 모델.
- Logistic Regression : 독립 변수와 종속변수의 선형 관계성.
- Decision Tree : 데이터 균일도에 따른 규칙.
- Support Vector Machine : 개별 클래스 간 최대 분류 마진.
- Nearest Neighbor : 근접 거리
- Neural Network : 심층 연결
- Ensemble : 서로 다른(같은) 머신러닝 알고리즘 결합.
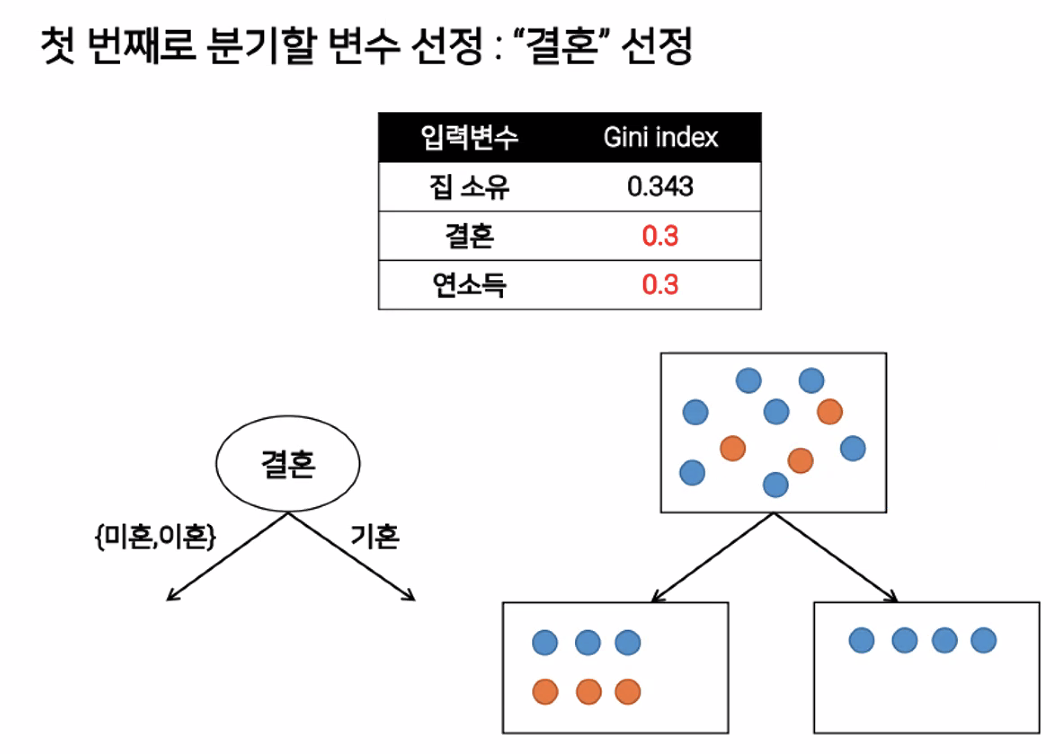
▶ Decision Trees
- 데이터의 의한 결과를 출력하는 조건(규칙)을 도출하는 기능.
- 심플하고 강력한 알고리즘.
- 캐글에서 많이 사용됨.
- 엔트로피 기반.
- 편향분산에 취약.

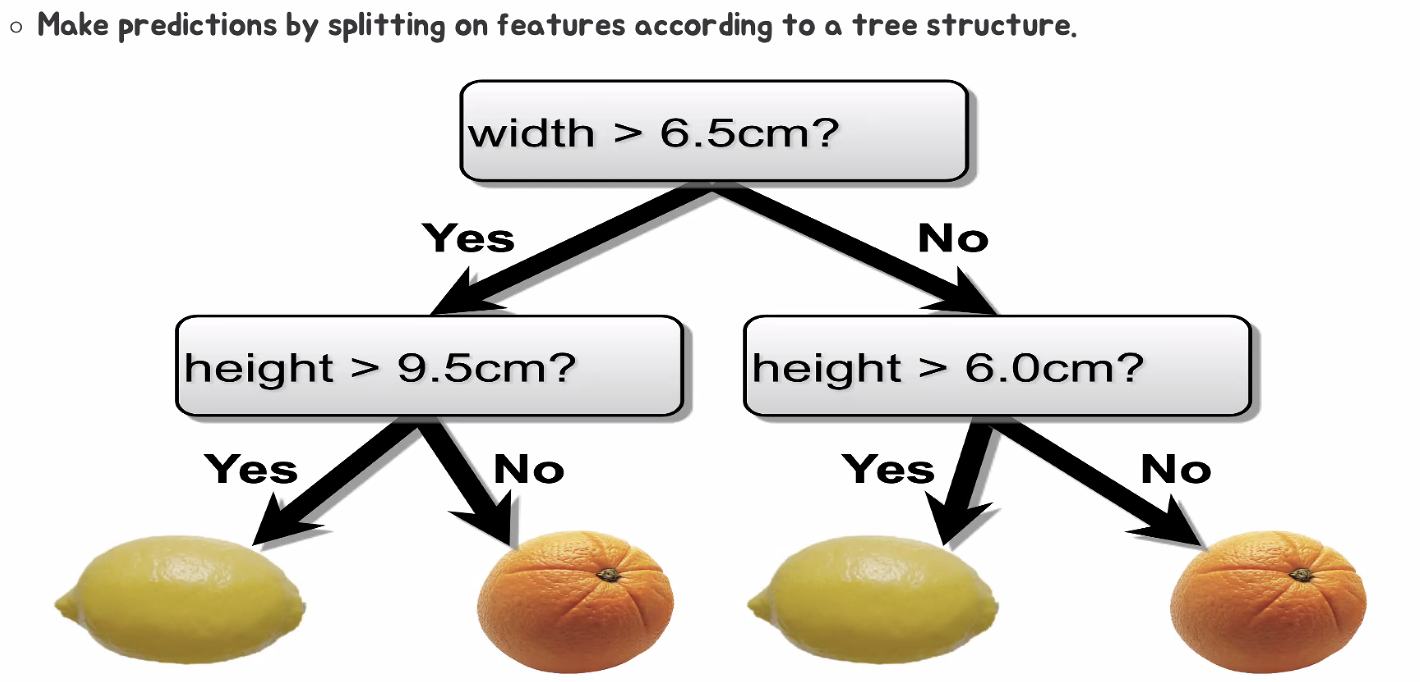
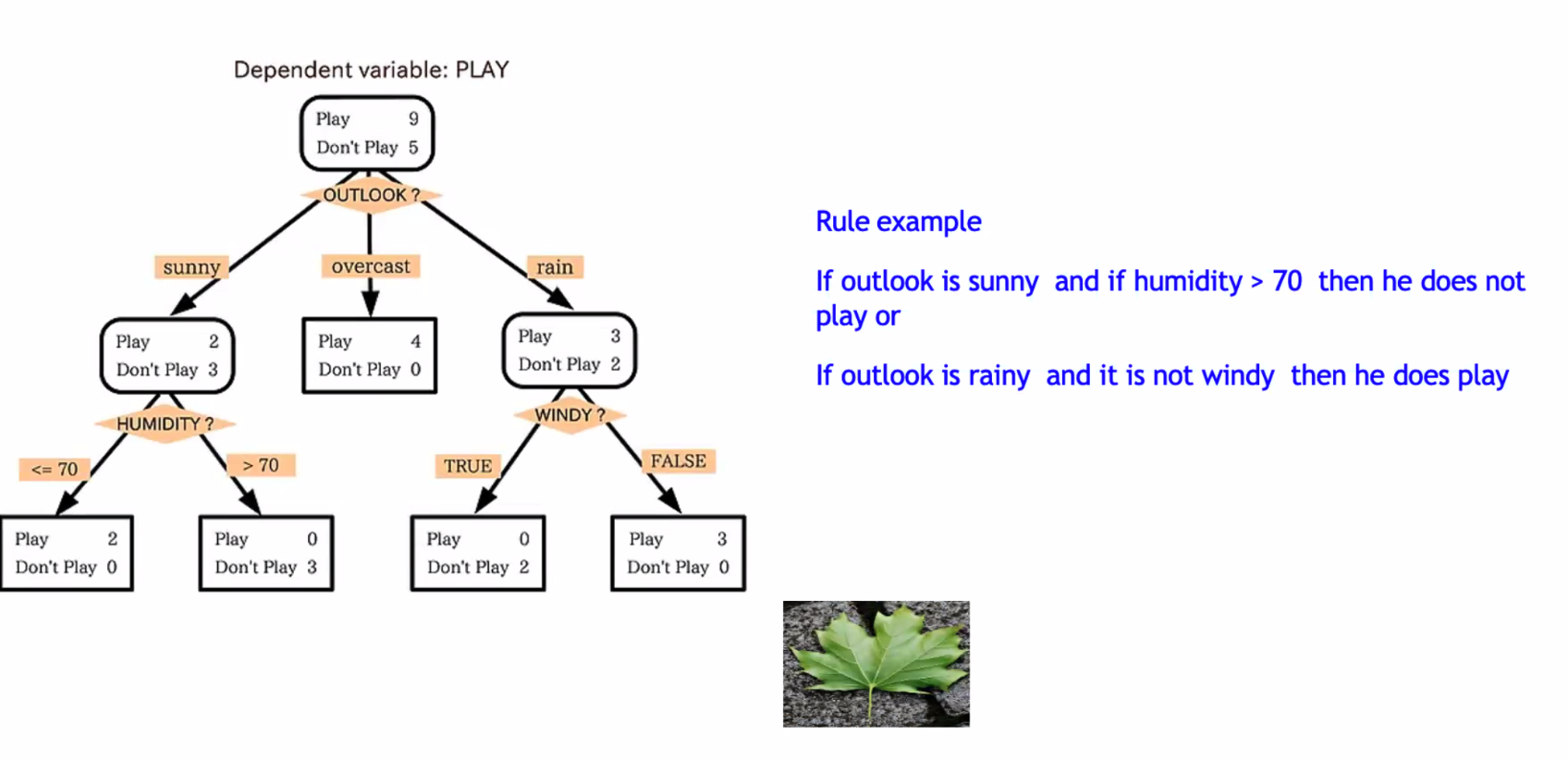

▶ 포유류 분류 예시
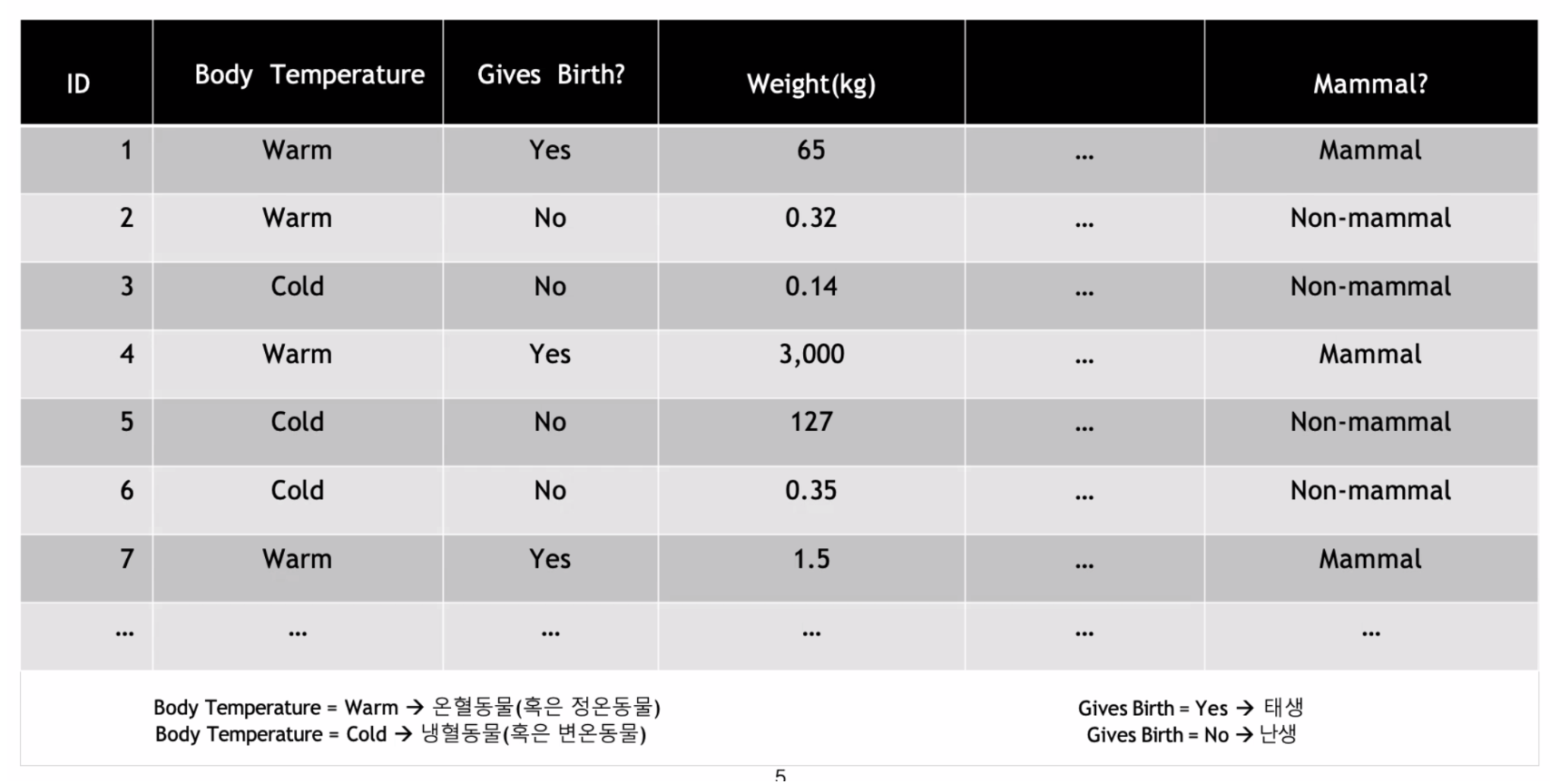

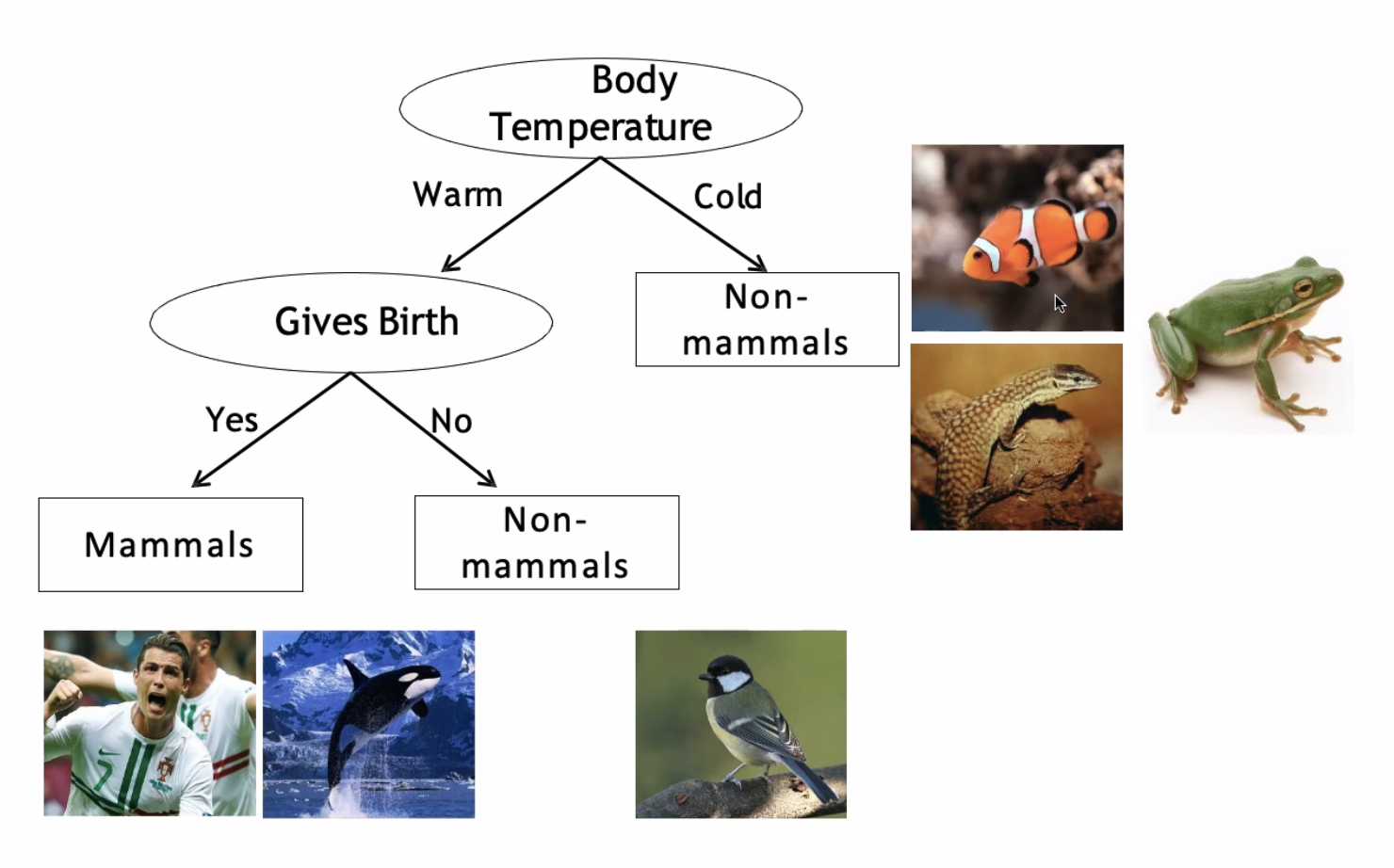
▷ 균일도
조건의 결과가 참과 거짓으로 나누고 이 중 균일도가 가장 높은것으로 판단한다.


▷ 채무불이행자분류 직접 구현.
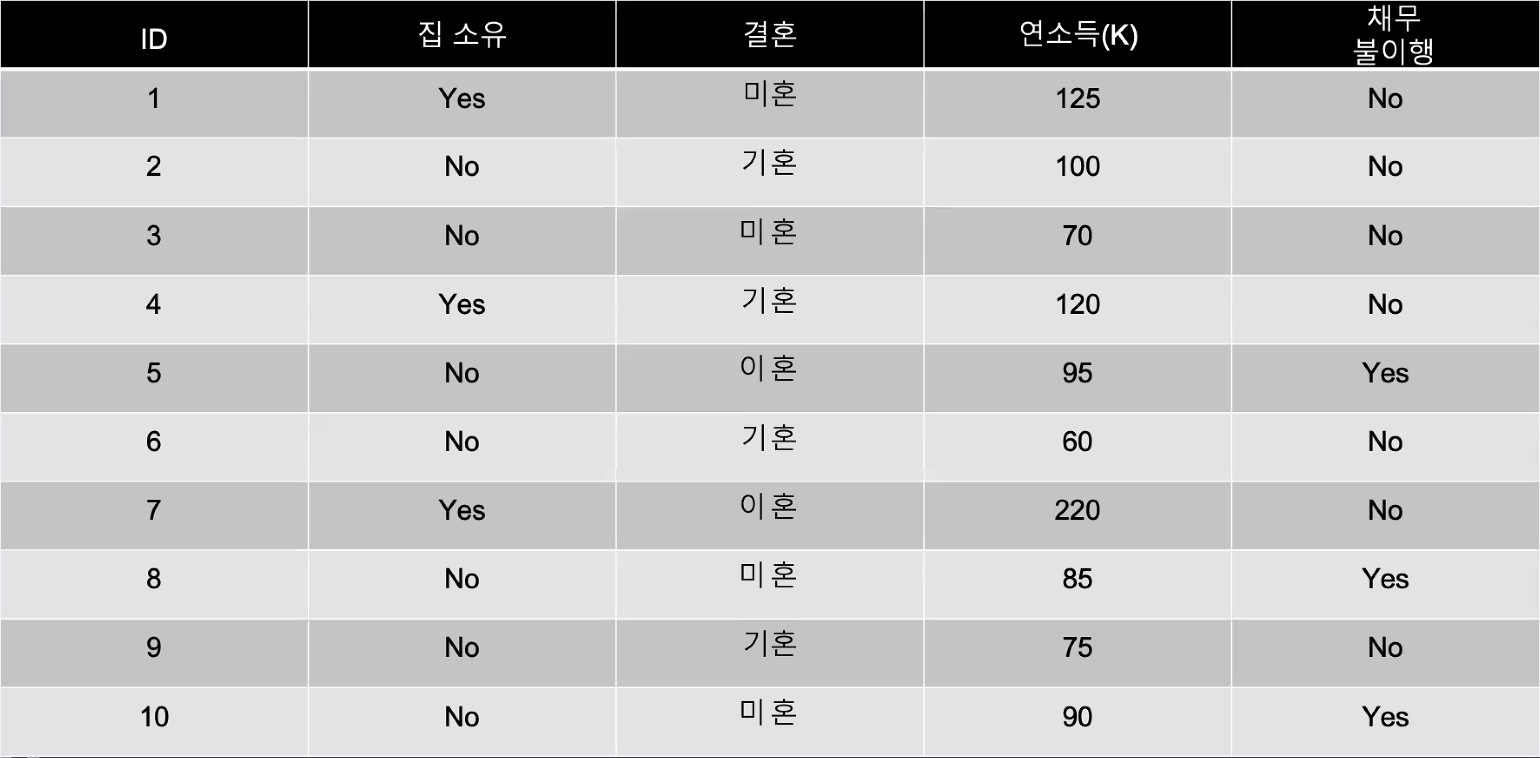
def solution(s) :
answer = 'Yes'
if s['집 소유'] <= 'No' :
if s['결혼'] != '기혼' :
if s['연소득'] > 70 and s['연소득'] <= 95 : answer = 'Yes'
else : answer = "No"
else : answer = "No"
else : answer = "No"
return answer→ 직접 구현하는데 오랜 시간이 걸리나 이를 Decision Tree가 해결해준다.
▷ 채무불이행자분류 Decision Trees 구현.


▶ 과적합 문제
한쪽으로 편향된 데이터를 예측하는 오류가 발생한다.

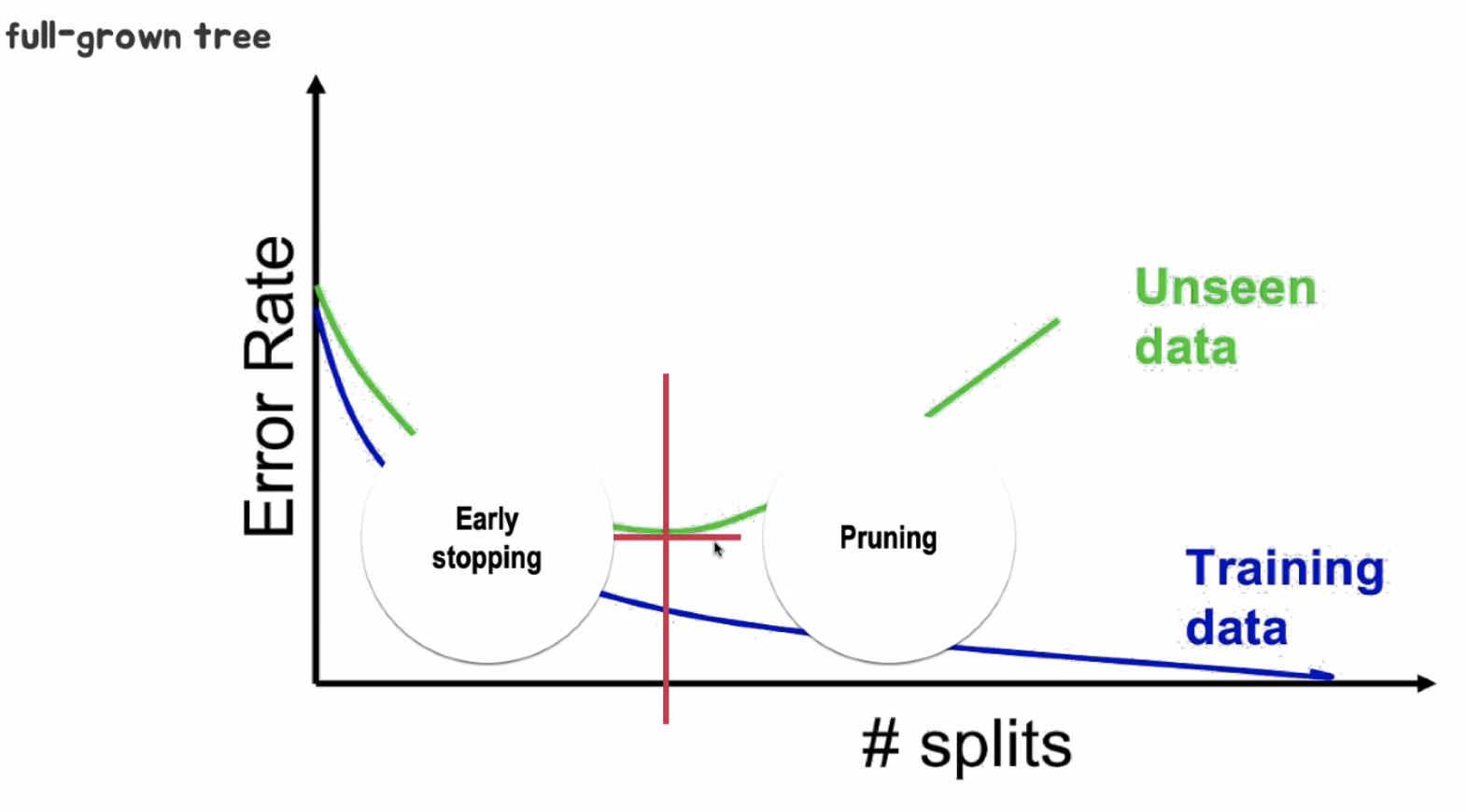
▶ REGULARIZATION (제약)
Regularziation은 모델의 복잡도에 대한 제약(혹은 penalty)을 학습 과정에 반영하는 것.
- 학습 데이터에 너무 Overfitting(과적합)하여 새롭게 등장하는 데이터에 대한 예측 성능이 떨어지는것을 방지함.
- Generalization
- 편향 분산 트레이드오프(Bias variance tradeoff)
▶ 최적의 지점
▶의사결정 나무 제약 PARAMETER
▷ 나무 구조 제한
- 나무 깊이 제한 (sklearn, max_depth)
- 리프 노드 수 제한 (sklearn, max_leaf nodes)
▷ 분순도 기준
- 분기를 발생시키는 최소 불순도 선정 (sklearn, min_impority_split)
- 분기를 일으켰을 때, 최소한의 분순도 감소폭을 설정 (sklearn, min_impurity_decrease)

▶ 실행
▷ 데이터 전처리
fin = {'ID': list(range(1, 11)),
'집 소유' : ['Yes', 'No', 'No', 'Yes', 'No', 'No', 'Yes', 'No', 'No', 'No'],
'결혼' : ['미혼', '기혼', '미혼', '기혼', '이혼', '기혼', '이혼', '미혼', '기혼', '미혼'],
'연소득' : [125, 100, 70, 120, 95, 60, 220, 85, 75, 90],
'채무 불이행' : ['No', 'No', 'No', 'No', 'Yes', 'No', 'No', 'Yes', 'No', 'Yes']}
df = pd.DataFrame(fin)
df.set_index('ID', inplace=True)# Labeling으로 문자형 데이터를 숫자형으로 변환
for i in ['집 소유', '결혼', '채무 불이행']:
globals()[f'df_{i}_encoder'] = LabelEncoder()
globals()[f'df_{i}_encoder'].fit(df[i])
df[i] = globals()[f'df_{i}_encoder'].transform(df[i])▷ 데이터와 결과를 머신러닝에 입력.
# 머신러닝이 목적으로 할 데이터를 설정
X = df.drop(columns='채무 불이행')
y = df['채무 불이행']from sklearn.tree import DecisionTreeClassifier
finan_dtclf = DecisionTreeClassifier()▷ 머신러닝에 학습
# fit = 머신러닝의 학습의 의미
finan_dtclf.fit(X, y)▷ graphviz 설치
# mac은 brew install graphviz
# window는 아나콘다 창에서 conda install graphvizfrom sklearn.tree import export_graphviz
import graphviz▷ 규칙 확인
export_graphviz(finan_dtclf, out_file='finance1.dot',
feature_names=X.columns,
class_names=['이행', '불이행'],
max_depth=None,
filled=True,
leaves_parallel=False,
impurity=True,
node_ids=False,
proportion=False,)
with open('./finance1.dot') as f :
finance1 = f.read()
graphviz.Source(finance1)
▷ 새로운 데이터를 가져온다.
new = ({'ID': list(range(1, 6)),
'집 소유' : ['No', 'Yes', 'Yes', 'No', 'No'],
'결혼' : ['미혼', '기혼', '미혼', '기혼', '이혼'],
'연소득(K)' : [55, 80, 110, 95, 300]
})
new_p = pd.DataFrame(new)
new_p.set_index('ID', inplace=True)
# Labeling으로 문자형 데이터를 숫자형으로 변환
for i in ['집 소유', '결혼']:
globals()[f'new_p{i}_encoder'] = LabelEncoder()
globals()[f'new_p{i}_encoder'].fit(new_p[i])
new_p[i] = globals()[f'new_p{i}_encoder'].transform(new_p[i])▷ 데이터를 머신러닝에 입력한다.
# predict() = 예측을 하겠다.
pred_result = finan_dtclf.predict(new_p)
pred_result_2 = df_채무불이행_encoder.inverse_transform(pred_result)
new_p['채무불이행예측'] = pred_result_2
new_p
▷ 데이터 프레임의 변수들을 다시 변경.
for i in ['집 소유', '결혼']:
new_p[i] = globals()[f'new_p{i}_encoder'].classes_[new_p[i]]
new_p
▶ 계산 복잡도
- 예측을 하기 위해 결정 트리를 루트 노드에서부터 리프 노드 까지 탐색해야 함.
- 일반적으로 결정 트리는 거의 균형을 이루고 있으므로 결정 트리를 탐색하기 위해서는 약O(log2(m))개의 노드를 거쳐야 함.
- 각 노드는 하나의 특성값만 확인하기 때문에 예측에 필요한 전체 복잡도를 특서 수와 무관하게 O(log2(m))이며 큰 훈련 세트를 다룰 때에도 예측 속도가 매우 빠름.
- 훈련 알고리즘은 각 노드에서 모든 훈련 샘플의 모든(또는 max_features 가 지정되었다면 그보다는 적은) 특성을 비교
- 각 노드에서 모든 샘플의 모든 특성을 비교하면 훈련 복잡도는 O(n X mlog2(m))
- 훈련 세트(수천 개 이하의 샘플)가 작을 경우 사이킷런은(presort = True로 지정하면) 미리 데이터를 정렬하여 훈련 속도를 높일 수 있으나, 훈련 세트가 큰 경우에는 속도가 많이 느려짐.
▶ 지니 분순도 & 엔트로피
- 기본적으로 지니 분순도를 사용, criterion 매개변수를 'entropy'로 지정하여 엔트로피 분순도를 사용할 수 있음.
- 엔트로피 : 분자의 무질서함을 측정하는 열역학의 개념
- 분자가 안정되고 질서 정연할 수 록 엔트로피는 0에 가까움.
- 메시지의 평균 정보 양을 측정하는 섀넌의 정보 이론 : 모든 메세지가 동일 할 때 엔트로피는 0.
- 엔트로피 : 분자의 무질서함을 측정하는 열역학의 개념
- 지니 불순도 VS 엔트로피
- 실제로는 큰 차이가 없이 비슷한 트리를 만든다.
- 지니 불순도가 조금 더 계산이 빠르기 때문에 기본값으로 좋다.
- 다른 트리가 만들어지는 경우 지니 불순도가 가장 빈도 높은 클래스를 한쪽 가지로 고립시키는 경향이 있는 반면 엔트로피는 조금 더 균형 잡힌 트리를 만든다.
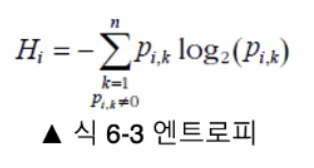
▶ 규제 매개변수
- 결정 트리는 훈련 데이터에 대한 제약 사항이 거의 없다.
- 선형 모델은 데이터가 선형일 거라 가정.
- 제한을 두지 않으면 트리가 훈련 데이터에 아주 가깝게 맞추려하기 때문에 과대적합되기 쉬움.
- 결정 트리는 모델 파라미터가 전혀 없는 것이 아니라(많이 있음), 훈련 되기 전에 파라미터 수가 결정되지 않고 이런 모델을 비파라미터 모델 이라고 부름.
- 모델 구조가 데이터에 맞춰져서 고정되지 않고 자유로움.
- 선형 모델 같은 파라미터 모델은 미리 정의된 모델 파라미터 수를 가지므로 자유도가 제한되고 과대적합될 위험이 줄어들며 과소적합될 위험은 커짐.

▶ 회귀
Decision TreeRegressor를 사용해 데이터셋에서 max_depth=2

▶ 타이타닉 데이터 생존 여부 예측
▶ 타이타닉 데이터 전처리.
# 타이타닉 데이터 전처리
df_t = sns.load_dataset('titanic')
df_t.drop(columns=['class', 'alive', 'embark_town', 'who', 'adult_male', 'alone'], inplace=True)
# 연령의 결측치 해결
age_md = df_t.groupby(['pclass', 'sex']).age.agg(['median'])
df_t.loc[(df_t['sex'] == 'male') & (df_t['pclass'] == 1) & (df_t.age.isna()), "age"] = age_md.loc[1, 'male'][0]
df_t.loc[(df_t['sex'] == 'male') & (df_t['pclass'] == 2) & (df_t.age.isna()), "age"] = age_md.loc[2, 'male'][0]
df_t.loc[(df_t['sex'] == 'male') & (df_t['pclass'] == 3) & (df_t.age.isna()), "age"] = age_md.loc[3, 'male'][0]
df_t.loc[(df_t['sex'] == 'female') & (df_t['pclass'] == 1) & (df_t.age.isna()), "age"] = age_md.loc[1, 'female'][0]
df_t.loc[(df_t['sex'] == 'female') & (df_t['pclass'] == 2) & (df_t.age.isna()), "age"] = age_md.loc[2, 'female'][0]
df_t.loc[(df_t['sex'] == 'female') & (df_t['pclass'] == 3) & (df_t.age.isna()), "age"] = age_md.loc[3, 'female'][0]
# embarked 결측치 해결
df_t.embarked.fillna(df_t.embarked.unique()[0], inplace=True)
# 연령층 별 컬럼 생성.
df_t.loc[df_t.age >= 50, "age_new"] = "old"
df_t.loc[(df_t.age < 50) & (df_t.age>=10), "age_new"] = "young"
df_t.loc[df_t.age < 10, "age_new"] = "baby"
# 불필요 컬럼 제거
df_t.drop(columns=['deck', 'sibsp', 'parch', 'age', 'embarked'], inplace=True)
# df_t.info()
# sex, embarked, age_new 해결해야함
# Labeling으로 문자형 데이터를 숫자형으로 변환
for i in ['sex', 'survived', 'age_new']:
globals()[f'df_t{i}_encoder'] = LabelEncoder()
globals()[f'df_t{i}_encoder'].fit(df_t[i])
df_t[i] = globals()[f'df_t{i}_encoder'].transform(df_t[i])
df_t
▶ 머신러닝 학습
# 타이타닉 머신러닝 예측 학습
# 머신러닝이 목적으로 할 데이터를 설정
X = df_t.drop(columns='survived')
y = df_t['survived']
from sklearn.tree import DecisionTreeClassifier
finan_dtclf_2 = DecisionTreeClassifier()
# fit = 머신러닝의 학습의 의미
finan_dtclf_2.fit(X, y)
# 분석-decision tree classification
from sklearn.tree import export_graphviz
import graphviz
export_graphviz(finan_dtclf_2, out_file='finance2.dot',
feature_names=X.columns,
class_names=['생존', '사망'],
max_depth=5,
filled=True,
leaves_parallel=False,
impurity=True,
node_ids=False,
proportion=False,)
with open('./finance2.dot') as f :
finance2 = f.read()
graphviz.Source(finance2)
# dot_graph의 source 저장
dot = graphviz.Source(finance2)
# png로 저장
dot.render(filename='tree.png')
{kind=link}
▶ 새롭게 들어온 타이타닉 데이터 전처리.
# 새로운 타이타닉 데이터 전처리
df_test = pd.read_csv('./test.csv')
# df_test.info()
# Name, Sex, Ticket, Cabin, Embarked 해결 필요
# 연령의 결측치 해결
age_md = df_test.groupby(['Pclass', 'Sex']).Age.agg(['median'])
for i in ['male', 'female'] :
for y in range(1, 4) :
f"df_test.loc[(df_test['Sex'] == '{i}') & (df_test['Pclass'] == {y}) & (df_test.Age.isna()), 'Age'] = age_md.loc[{y}, '{i}'][0]"
# fare 결측치 해결
fare_md = df_test.groupby(['Pclass', 'Sex']).Fare.agg(['median'])
for i in ['male', 'female'] :
for y in range(1, 4) :
f"df_test.loc[(df_test['Sex'] == '{i}') & (df_test['Pclass'] == {y}) & (df_test.Fare.isna()), 'Fare'] = fare_md.loc[{y}, '{i}'][0]"
# 결측치가 너무 많은 데이터, 컬럼 삭제
df_test.drop(columns=['Cabin'], inplace=True)
# age_new 생성
df_test.loc[df_test.Age >= 50, "age_new"] = "old"
df_test.loc[(df_test.Age < 50) & (df_test.Age>=10), "age_new"] = "young"
df_test.loc[df_test.Age < 10, "age_new"] = "baby"
# 필요 없는 데이터 제거
df_test.drop(columns=['Name', 'Ticket', 'PassengerId', "SibSp", "Parch", 'Age', 'Embarked'], inplace=True)
# 컬럼 소문자로 변경
l1 = []
for i in list(df_test.columns):
l1.append(i.lower())
df_test.set_axis(l1, axis='columns', inplace=True)
# Index(['pclass', 'sex', 'age', 'fare', 'embarked', 'predict survived'], dtype='object')
# Labeling으로 문자형 데이터를 숫자형으로 변환
for i in ['sex', 'age_new']:
globals()[f'df_test{i}_encoder'] = LabelEncoder()
globals()[f'df_test{i}_encoder'].fit(df_test[i])
df_test[i] = globals()[f'df_test{i}_encoder'].transform(df_test[i])
df_test
▶ 생존여부의 결과를 입력.
# 새로운 타이타닉 데이터 생존 여부 예측
pred_result = finan_dtclf_2.predict(df_test)
pred_result_2 = df_tsurvived_encoder.inverse_transform(pred_result)
df_test['survived'] = pred_result_2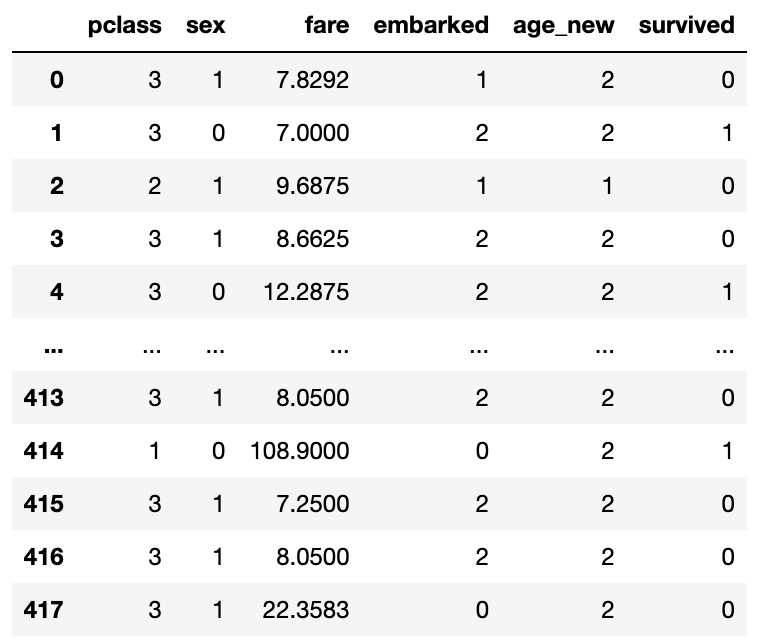
▶ 파일 저장.
# 파일 저장해서 캐글에 올리기.
tit = pd.read_csv('test.csv')
tit.drop(list(tit.columns)[1:], axis = 1, inplace=True)
tit['Survived'] = df_test['survived']
tit.set_index('PassengerId', inplace=True)
tit.to_csv('tit_test.csv')
'Python' 카테고리의 다른 글
| [Python] Coding Test (팩토리얼) (0) | 2022.10.13 |
|---|---|
| [Python] Coding Test (이진수 변환) (0) | 2022.10.13 |
| [Python] 빅데이터 분석 2 : 데이터 전처리(Data Preprocessing) (0) | 2022.10.11 |
| [Python] 빅데이터 분석 1 : 데이터 수집(Data Collection) (0) | 2022.10.11 |
| [Python] Coding Test (프린터) (0) | 2022.10.10 |